一、项目说明

检索系统存在于我们日常使用的很多产品中,比如商品搜索系统、学术文献检索系,短视频相关性推荐等等,本方案提供了检索系统完整实现。限定场景是用户通过输入检索词 Query,快速在海量数据中查找相似文档。
所谓语义检索(也称基于向量的检索),是指检索系统不再拘泥于用户 Query 字面本身,而是能精准捕捉到用户 Query 后面的真正意图并以此来搜索,从而更准确地向用户返回最符合的结果。通过使用最先进的语义索引模型找到文本的向量表示,在高维向量空间中对它们进行索引,并度量查询向量与索引文档的相似程度,从而解决了关键词索引带来的缺陷。
例如下面两组文本 Pair,如果基于关键词去计算相似度,两组的相似度是相同的。而从实际语义上看,第一组相似度高于第二组。
车头如何放置车牌 前牌照怎么装 车头如何放置车牌 后牌照怎么装
语义检索系统的关键就在于,采用语义而非关键词方式进行召回,达到更精准、更广泛得召回相似结果的目的。
通常检索业务的数据都比较庞大,都会分为召回(索引)、排序两个环节。召回阶段主要是从至少千万级别的候选集合里面,筛选出相关的文档,这样候选集合的数目就会大大降低,在之后的排序阶段就可以使用一些复杂的模型做精细化或者个性化的排序。一般采用多路召回策略(例如关键词召回、热点召回、语义召回结合等),多路召回结果聚合后,经过统一的打分以后选出最优的 TopK 的结果。
本项目基于PaddleNLP Neural Search。
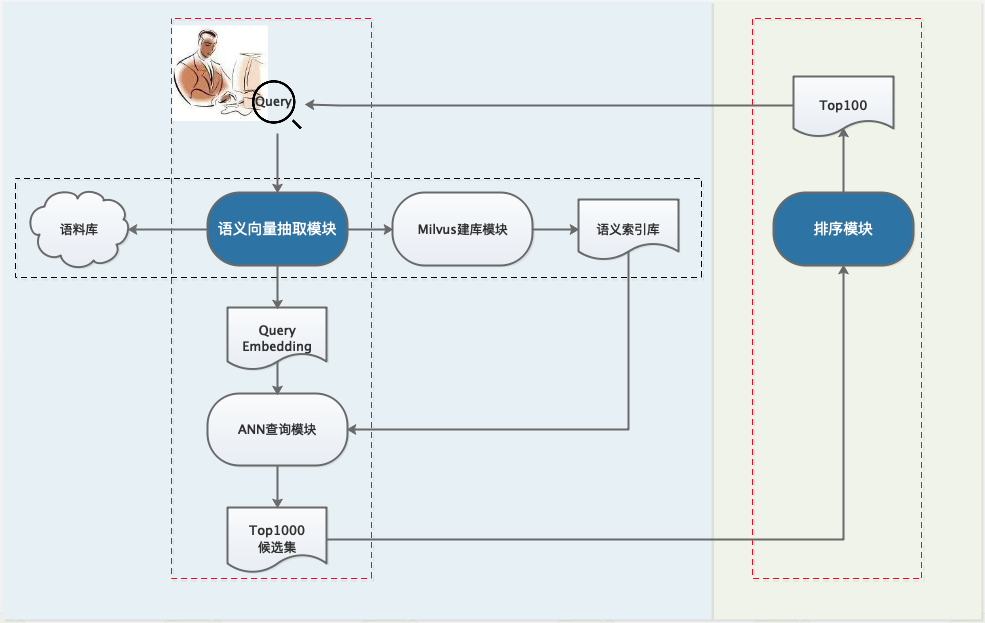
以下是Neural Search的系统流程图,其中左侧为召回环节,核心是语义向量抽取模块;右侧是排序环节,核心是排序模型。图中红色虚线框表示在线计算,黑色虚线框表示离线批量处理。下面我们分别介绍召回中的语义向量抽取模块,以及排序模型。
如果对您有帮助,欢迎star收藏一下,不易走丢哦~链接指路:https://github.com/PaddlePaddle/PaddleNLP

语义检索系统也有视频课程上线啦,课程直通车点击这里### PaddleNLP Neural Search 系统特色
低门槛
手把手搭建起检索系统
无需标注数据也能构建检索系统
提供 训练、预测、ANN 引擎一站式能力
效果好
仅有无监督数据: SimCSE
仅有有监督数据: InBatchNegative
兼具无监督数据 和 有监督数据:融合模型
针对多种数据场景的专业方案
进一步优化方案: 面向领域的预训练 Domain-adaptive Pretraining
性能快
基于 Paddle Inference 快速抽取向量
基于 Milvus 快速查询和高性能建库## 二、安装说明
AI Studio平台默认安装了Paddle和PaddleNLP,并定期更新版本。 如需手动更新,可参考如下说明:
paddlepaddle >= 2.2
安装文档PaddleNLP >= 2.2
使用如下命令确保安装最新版PaddleNLP:
!pip install --upgrade paddlenlp
python >= 3.6 # 首先通过如下命令安装最新版本的 paddlenlp
!pip install --upgrade paddlenlp在项目开始之前,我们首先导入相关的库包。# 导入系统库
import abc
import sys
from functools import partial
import argparse
import os
import random
import time
#导入python的其他库
import numpy as np
from scipy import stats
import pandas as pd
from tqdm import tqdm
from scipy.special import softmax
from scipy.special import expit
#导入Paddle库
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle import inference
#导入PaddleNLP相关的库
import paddlenlp as ppnlp
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.datasets import load_dataset, MapDataset
from paddlenlp.transformers import LinearDecayWithWarmup
from paddlenlp.utils.downloader import get_path_from_url
from visualdl import LogWriter
from data import convert_pairwise_example## 三、召回模型方案实践
方案简介
首先利用业务上的无标注数据对SimCSE上进行无监督训练,训练导出模型,然后利用In-batch Negatives的策略在有监督数据上进行训练得到最终的召回模型。利用召回模型抽取向量,然后插入到Milvus召回系统中,进行召回。
无监督语义索引
数据准备
我们基于开源的文献检索数据集构造生成了面向语义索引的训练集、评估集、召回库。
采用文献的 query,title,keywords 三个字段内容,构造无标签数据集,每一行只有一条文本,要么是query,要么就是title和keywords的拼接句子。
样例数据如下:
睡眠障碍与常见神经系统疾病的关系睡眠觉醒障碍,神经系统疾病,睡眠,快速眼运动,细胞增殖,阿尔茨海默病 城市道路交通流中观仿真研究 城市道路交通流中观仿真研究智能运输系统;城市交通管理;计算机仿真;城市道路;交通流;路径选择 网络健康可信性研究 网络健康可信性研究网络健康信息;可信���;评估模式 脑瘫患儿家庭复原力的影响因素及干预模式雏形 研究 脑瘫患儿家庭复原力的影响因素及干预模式雏形研究脑瘫患儿;家庭功能;干预模式 地西他滨与HA方案治疗骨髓增生异常综合征转化的急性髓系白血病患者近期疗效比较 地西他滨与HA方案治疗骨髓增生异常综合征转化的急性髓系白血病患者近期疗效比较 个案工作 社会化 个案社会工作介入社区矫正再社会化研究——以东莞市清溪镇为例社会工作者;社区矫正人员;再社会化;角色定位 圆周运动加速度角速度 圆周运动向心加速度物理意义的理论分析匀速圆周运动,向心加速度,物理意义,角速度,物理量,线速度,周期
注:这里采用少量demo数据用于演示训练流程。预测阶段直接调用基于全量数据训练出来的模型进行预测。
全量数据和所有模型均已开源,见PaddleNLP Neural Search。# 数据读取逻辑
def read_simcse_text(data_path):
“”“Reads data.”""
with open(data_path, ‘r’, encoding=‘utf-8’) as f:
for i,line in enumerate(f):
if(i==0):
continue
data = line.rstrip()
# 这里的text_a和text_b是一样的
yield {‘text_a’: data, ‘text_b’: data}
train_set_file=‘train_demo.csv’
train_ds = load_dataset(read_simcse_text, data_path=train_set_file, lazy=False)
#展示3条数据
for i in range(3):
print(train_ds[i])打印结果可以看出,输入数据的两条文本是一样的。#### 构建Dataloader
在训练神经网络之前,我们需要构建小批量的数据,所以需要借助Dataloader,在组装小批量的数据的之前我们认识一下下面的API:
| API | 简介 |
|---|---|
paddlenlp.data.Stack | 堆叠N个具有相同shape的输入数据来构建一个batch |
paddlenlp.data.Pad | 将长度不同的多个句子padding到统一长度,取N个输入数据中的最大长度 |
paddlenlp.data.Tuple | 将多个batchify函数包装在一起 |
更多数据处理操作详见: https://paddlenlp.readthedocs.io/zh/latest/data_prepare/data_preprocess.html# 由于文本是序列数据,数据对齐。如下面会对每个序列补0,和a的长度保持一致
a = [1, 2, 3, 4]
b = [5, 6, 7]
c = [8, 9]
result = Pad(pad_val=0)([a, b, c])
print(“Padded data: \n”, result)
print()
#组装minibatch需要使用
a = [1, 2, 3, 4]
b = [3, 4, 5, 6]
c = [5, 6, 7, 8]
result = Stack()([a, b, c])
print(“Stacked data: \n”, result)
print()
data = [
[[1, 2, 3, 4], [1]],
[[5, 6, 7], [0]],
[[8, 9], [1]],
]
batchify_fn = Tuple(Pad(pad_val=0), Stack())
ids, labels = batchify_fn(data)
print(“ids: \n”, ids)
print()
print(“labels: \n”, labels)
print()# 明文数据 -> ID 序列训练数据
def create_dataloader(dataset,
mode=‘train’,
batch_size=1,
batchify_fn=None,
trans_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False if mode == 'train': # 分布式批采样器加载数据的一个子集。 # 每个进程可以传递给DataLoader一个DistributedBatchSampler的实例,每个进程加载原始数据的一个子集。 batch_sampler = paddle.io.DistributedBatchSampler( dataset, batch_size=batch_size, shuffle=shuffle) else: # 批采样器的基础实现, # 用于 paddle.io.DataLoader 中迭代式获取mini-batch的样本下标数组,数组长度与 batch_size 一致。 batch_sampler = paddle.io.BatchSampler( dataset, batch_size=batch_size, shuffle=shuffle) # 组装mini-batch return paddle.io.DataLoader( dataset=dataset, batch_sampler=batch_sampler, collate_fn=batchify_fn, return_list=True)
def convert_example(example, tokenizer, max_seq_length=512, do_evalute=False):
result = [] for key, text in example.items(): if 'label' in key: # do_evaluate result += [example['label']] else: # do_train encoded_inputs = tokenizer(text=text, max_seq_len=max_seq_length) input_ids = encoded_inputs["input_ids"] token_type_ids = encoded_inputs["token_type_ids"] result += [input_ids, token_type_ids] return result
#语义索引的维度最大为64,可以根据自己的情况调节长度
max_seq_length=64
#根据经验 batch_size越大效果越好
batch_size=32
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained(‘ernie-1.0’)
#给convert_example赋予默认的值,如tokenizer,max_seq_length
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
#[pad]对齐的函数
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # query_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # query_segment
Pad(axis=0, pad_val=tokenizer.pad_token_id), # title_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # tilte_segment
): [data for data in fn(samples)]
#构建训练的Dataloader
train_data_loader = create_dataloader(
train_ds,
mode=‘train’,
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)展示一下输入的dataloader的数据for idx, batch in enumerate(train_data_loader):
if idx == 0:
print(batch)
break上面展示的是一个batch的数据,包含两个Tensor,第一个Tensor表示的是input_ids,第二个Tensor表示的是token_type_ids;第一个Tensor中,32是batch_size的维度,64代表的是序列的长度,表示输入的文本的最大长度是64;第二个Tensor中,32表示的也是batch_size,64表示的是序列的长度。####
模型构建
接下来搭建SimCSE模型,主要部分是用query和title分别得到embedding向量,然后计算余弦相似度。
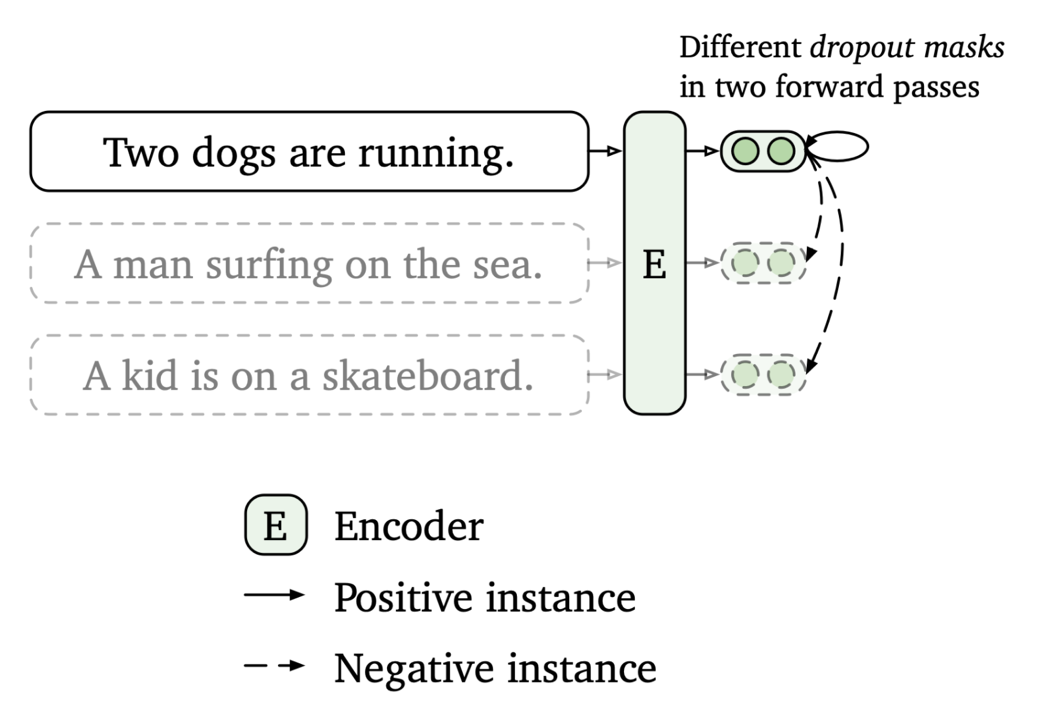
上图是SimCSE的原理图,SimCSE主要是通过dropout来把同一个句子变成正样本(做两次前向,但是dropout有随机因素,所以产生的向量不一样,但是本质上还是表示的是同一句话),把一个batch里面其他的句子变成负样本的。class
SimCSE(nn.Layer):
def init(self,
pretrained_model,
dropout=None,
margin=0.0,
scale=20,
output_emb_size=None):
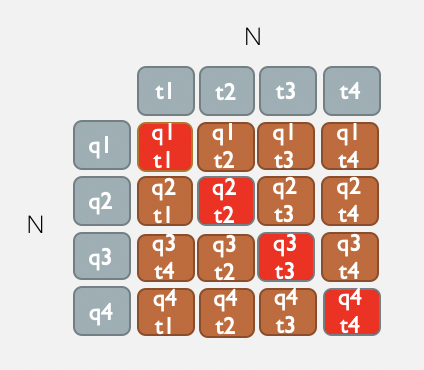
super().__init__() self.ptm = pretrained_model # 显式的加一个dropout来控制 self.dropout = nn.Dropout(dropout if dropout is not None else 0.1) # if output_emb_size is greater than 0, then add Linear layer to reduce embedding_size, # 考虑到性能和效率,我们推荐把output_emb_size设置成256 # 向量越大,语义信息越丰富,但消耗资源越多 self.output_emb_size = output_emb_size if output_emb_size > 0: weight_attr = paddle.ParamAttr( initializer=nn.initializer.TruncatedNormal(std=0.02)) self.emb_reduce_linear = paddle.nn.Linear( 768, output_emb_size, weight_attr=weight_attr) self.margin = margin # 为了使余弦相似度更容易收敛,我们选择把计算出来的余弦相似度扩大scale倍,一般设置成20左右 self.sacle = scale # 加入jit注释能够把该提取向量的函数导出成静态图 # 对应input_id,token_type_id两个 @paddle.jit.to_static(input_spec=[paddle.static.InputSpec(shape=[None, None], dtype='int64'),paddle.static.InputSpec(shape=[None, None], dtype='int64')]) def get_pooled_embedding(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None, with_pooler=True): # Note: cls_embedding is poolerd embedding with act tanh sequence_output, cls_embedding = self.ptm(input_ids, token_type_ids, position_ids, attention_mask) if with_pooler == False: cls_embedding = sequence_output[:, 0, :] if self.output_emb_size > 0: cls_embedding = self.emb_reduce_linear(cls_embedding) cls_embedding = self.dropout(cls_embedding) # https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/functional/normalize_cn.html cls_embedding = F.normalize(cls_embedding, p=2, axis=-1) return cls_embedding def forward(self, query_input_ids, title_input_ids, query_token_type_ids=None, query_position_ids=None, query_attention_mask=None, title_token_type_ids=None, title_position_ids=None, title_attention_mask=None): # 第 1 次编码: 文本经过无监督语义索引模型编码后的语义向量 # [N, 768] query_cls_embedding = self.get_pooled_embedding( query_input_ids, query_token_type_ids, query_position_ids, query_attention_mask) # 第 2 次编码: 文本经过无监督语义索引模型编码后的语义向量 # [N, 768] title_cls_embedding = self.get_pooled_embedding( title_input_ids, title_token_type_ids, title_position_ids, title_attention_mask) # 相似度矩阵: [N, N] cosine_sim = paddle.matmul( query_cls_embedding, title_cls_embedding, transpose_y=True) # substract margin from all positive samples cosine_sim() # 填充self.margin值,比如margin为0.2,query_cls_embedding.shape[0]=2 # margin_diag: [0.2,0.2] margin_diag = paddle.full( shape=[query_cls_embedding.shape[0]], fill_value=self.margin, dtype=paddle.get_default_dtype()) # input paddle.diag(margin_diag): [[0.2,0],[0,0.2]] # input cosine_sim : [[1.0,0.6],[0.6,1.0]] # output cosine_sim: [[0.8,0.6],[0.6,0.8]] cosine_sim = cosine_sim - paddle.diag(margin_diag) # scale cosine to ease training converge cosine_sim *= self.sacle # 转化成多分类任务: 对角线元素是正例,其余元素为负例 # labels : [0,1,2,3] labels = paddle.arange(0, query_cls_embedding.shape[0], dtype='int64') # labels : [[0],[1],[2],[3]] labels = paddle.reshape(labels, shape=[-1, 1]) # 交叉熵损失函数 loss = F.cross_entropy(input=cosine_sim, label=labels) return loss
上述代码的相似度矩阵计算示例如下:
#关键参数
scale=20 # 推荐值: 10 ~ 30
margin=0.1 # 推荐值: 0.0 ~ 0.2
#SimCSE的dropout的参数,也可以使用预训练语言模型默认的dropout参数
dropout=0.2
#向量映射的维度,默认的输出是768维,推荐通过线性层映射成256维
output_emb_size=256
#训练的epoch数目
epochs=1
weight_decay=0.0
#学习率
learning_rate=5E-5
warmup_proportion=0.0
加载预训练模型
加载预训练模型 ERNIE1.0 进行热启
定义优化器 AdamOptimizer# 设置ERNIE-1.0预训练模型
model_name_or_path=‘ernie-1.0’
pretrained_model = ppnlp.transformers.ErnieModel.from_pretrained(
model_name_or_path,
hidden_dropout_prob=dropout,
attention_probs_dropout_prob=dropout)
print(“loading model from {}”.format(model_name_or_path))
#实例化SimCSE��SimCSE使用的Encoder是ERNIE-1.0
model = SimCSE(
pretrained_model,
margin=margin,
scale=scale,
output_emb_size=output_emb_size)
#训练的总步数
num_training_steps = len(train_data_loader) * epochs
#warmpup操作,学习率先上升后下降
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps,
warmup_proportion)
#Generate parameter names needed to perform weight decay.
#All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in [“bias”, “norm”])
]
#设置优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
模型训练
上面的训练配置完毕以后,下面就可以开始训练了。save_dir=‘checkpoint’
save_steps=100
time_start=time.time()
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
query_input_ids, query_token_type_ids, title_input_ids, title_token_type_ids = batch
# 其中query和title为同一条数据
loss = model(
query_input_ids=query_input_ids,
title_input_ids=title_input_ids,
query_token_type_ids=query_token_type_ids,
title_token_type_ids=title_token_type_ids)
# 每隔10个step进行打印日志
global_step += 1
if global_step % 10 == 0:
print(“global step %d, epoch: %d, batch: %d, loss: %.5f, speed: %.2f step/s”
% (global_step, epoch, step, loss,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
#每隔save_steps保存模型
if global_step % save_steps == 0:
save_path = os.path.join(save_dir, “model_%d” % (global_step))
if not os.path.exists(save_path):
os.makedirs(save_path)
save_param_path = os.path.join(save_path, ‘model_state.pdparams’)
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_path)
time_end=time.time()
print(‘totally cost {} seconds’.format(time_end-time_start))
模型预测
由于本项目使用的demo数据,在预测部分为了保证效果,我们使用已经用全量数据训练好的模型,首先下载训练好的SimCSE模型,然后进行解压#
!wget https://bj.bcebos.com/v1/paddlenlp/models/simcse_model.zip
if(not os.path.exists(‘simcse_model.zip’)):
get_path_from_url(‘https://bj.bcebos.com/v1/paddlenlp/models/simcse_model.zip’,root_dir=’.’)
#解压SimCSE模型
!unzip -o simcse_model.zip -d pretrained/from data import convert_example_test
#加载预训练好的无监督语义��引模型 SimCSE
params_path=‘pretrained/model_20000/model_state.pdparams’
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
#定义两条文本数据
test_data = [‘国有企业引入非国有资本对创新绩效的影响——基于制造业国有上市公司的经验证据’, ‘语义检索相关的论文’]
#给convert_example_test赋予默认值
test_func = partial(
convert_example_test,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
#pad对齐操作
test_batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # text_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # text_segment
): [data for data in fn(samples)]
#conver_example function’s input must be dict
corpus_ds = MapDataset(test_data)
#构造Dataloader
corpus_data_loader = create_dataloader(
corpus_ds,
mode=‘predict’,
batch_size=batch_size,
batchify_fn=test_batchify_fn,
trans_fn=test_func)
all_embeddings = []
#切换成eval模式,固定住 dropout
model.eval()
#预测的时候不保存梯度
with paddle.no_grad():
for batch_data in corpus_data_loader:
input_ids, token_type_ids = batch_data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
# 抽取向量
text_embeddings = model.get_pooled_embedding(input_ids, token_type_ids)
all_embeddings.append(text_embeddings)
text_embedding=all_embeddings[0]
print(text_embedding.shape)
print(text_embedding.numpy())从输出结果可以看出,两条文本被抽取成了2条256维度的向量。
有监督语义索引
数据准备
使用文献的的query, title, keywords,构造带正标签的数据集,不包含负标签样本
宁夏社区图书馆服务体系布局现状分析 宁夏社区图书馆服务体系布局现状分析社区图书馆,社区图书馆服务,社区图书馆服务体系
人口老龄化对京津冀经济 京津冀���口老龄化对区域经济增长的影响京津冀,人口老龄化,区域经济增长,固定效应模型
英语广告中的模糊语 模糊语在英语广告中的应用及其功能模糊语,英语广告,表现形式,语用功能
甘氨酸二肽的合成 甘氨酸二肽合成中缩合剂的选择甘氨酸,缩合剂,二肽
```def read_text_pair(data_path):
"""Reads data."""
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
data = line.rstrip().split("\t")
if len(data) != 2:
continue
# 可以看到有监督数据使用query title pair的
# 所以text_a和text_b不一样
yield {'text_a': data[0], 'text_b': data[1]}
train_set_file='train.csv'
train_ds = load_dataset(
read_text_pair, data_path=train_set_file, lazy=False)
# 打印3条文本
for i in range(3):
print(train_ds[i])可以看到有监督的In-batch Negatives的训练输入的文本text_a,text_b是不一样的,表示的是text_a和text_b是相似的文本。#### 模型构建from base_model import SemanticIndexbase
class SemanticIndexBatchNeg(SemanticIndexbase):
def __init__(self,
pretrained_model,
dropout=None,
margin=0.3,
scale=30,
output_emb_size=None):
super().__init__(pretrained_model, dropout, output_emb_size)
self.margin = margin
# Used scaling cosine similarity to ease converge
self.sacle = scale
def forward(self,
query_input_ids,
title_input_ids,
query_token_type_ids=None,
query_position_ids=None,
query_attention_mask=None,
title_token_type_ids=None,
title_position_ids=None,
title_attention_mask=None):
query_cls_embedding = self.get_pooled_embedding(
query_input_ids, query_token_type_ids, query_position_ids,
query_attention_mask)
title_cls_embedding = self.get_pooled_embedding(
title_input_ids, title_token_type_ids, title_position_ids,
title_attention_mask)
cosine_sim = paddle.matmul(
query_cls_embedding, title_cls_embedding, transpose_y=True)
# substract margin from all positive samples cosine_sim()
margin_diag = paddle.full(
shape=[query_cls_embedding.shape[0]],
fill_value=self.margin,
dtype=paddle.get_default_dtype())
cosine_sim = cosine_sim - paddle.diag(margin_diag)
# scale cosine to ease training converge
cosine_sim *= self.sacle
labels = paddle.arange(0, query_cls_embedding.shape[0], dtype='int64')
labels = paddle.reshape(labels, shape=[-1, 1])
loss = F.cross_entropy(input=cosine_sim, label=labels)
return loss从模型层面来讲SimCSE的结构和Inbatch-Negatives的网络结构没有区别,唯一最大的区别是训练过程使用了有监督的数据。
#### 训练配置
定义模型训练的超参,优化器等等。
#关键参数
scale=20 # 推荐值: 10 ~ 30
margin=0.1 # 推荐值: 0.0 ~ 0.2
#最大序列长度
max_seq_length=64
epochs=1
learning_rate=5E-5
warmup_proportion=0.0
weight_decay=0.0
save_steps=10
batch_size=64
output_emb_size=256pretrained_model = ppnlp.transformers.ErnieModel.from_pretrained(
'ernie-1.0')
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained('ernie-1.0')
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # query_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # query_segment
Pad(axis=0, pad_val=tokenizer.pad_token_id), # title_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # tilte_segment
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# Inbatch-Negatives
model = SemanticIndexBatchNeg(
pretrained_model,
margin=margin,
scale=scale,
output_emb_size=output_emb_size)
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps,
warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params) #### 模型训练
模型训练过程如下:
1.从dataloader中取出小批量数据
2.输入到模型中做��向
3.求损失函数
3.反向传播更新梯度def do_train(model,train_data_loader):
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
query_input_ids, query_token_type_ids, title_input_ids, title_token_type_ids = batch
loss = model(
query_input_ids=query_input_ids,
title_input_ids=title_input_ids,
query_token_type_ids=query_token_type_ids,
title_token_type_ids=title_token_type_ids)
global_step += 1
if global_step % 5 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss,
10 / (time.time() - tic_train)))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % save_steps == 0:
save_path = os.path.join(save_dir, "model_%d" % global_step)
if not os.path.exists(save_path):
os.makedirs(save_path)
save_param_path = os.path.join(save_path, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_path)
do_train(model,train_data_loader)
#### 模型预测
模型预测部分加载训练好的模型,然后输入两条示例数据进行预测抽取向量。# !wget https://bj.bcebos.com/v1/paddlenlp/models/inbatch_model.zip
if(not os.path.exists('inbatch_model.zip')):
get_path_from_url('https://bj.bcebos.com/v1/paddlenlp/models/inbatch_model.zip',root_dir='.')
!unzip -o inbatch_model.zip -d pretrained/max_seq_length=64
output_emb_size=256
batch_size=1
params_path='pretrained/model_40/model_state.pdparams'
test_data = ["国有企业引入非国有资本对创新绩效的影��——基于制造业国有上市公司的经验证据"]
# 加载模型
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
test_func = partial(
convert_example_test,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
test_batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # text_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # text_segment
): [data for data in fn(samples)]
# conver_example function's input must be dict
corpus_ds = MapDataset(test_data)
corpus_data_loader = create_dataloader(
corpus_ds,
mode='predict',
batch_size=batch_size,
batchify_fn=test_batchify_fn,
trans_fn=test_func)
all_embeddings = []
model.eval()
with paddle.no_grad():
for batch_data in corpus_data_loader:
input_ids, token_type_ids = batch_data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
text_embeddings = model.get_pooled_embedding(input_ids, token_type_ids)
all_embeddings.append(text_embeddings)
text_embedding=all_embeddings[0]
print(text_embedding.shape)
print(text_embedding.numpy())### 模型部署
模型部署首先需要把模型转换成静态图模型。output_path='output/recall'
model.eval()
# Convert to static graph with specific input description
model = paddle.jit.to_static(
model,
input_spec=[
paddle.static.InputSpec(
shape=[None, None], dtype="int64"), # input_ids
paddle.static.InputSpec(
shape=[None, None], dtype="int64") # segment_ids
])
# Save in static graph model.
save_path = os.path.join(output_path, "inference")
paddle.jit.save(model, save_path)from data import convert_example_recall_infer
from scipy.special import softmax
from scipy import spatial
class RecallPredictor(object):
def __init__(self,
model_dir,
device="gpu",
max_seq_length=128,
batch_size=32,
use_tensorrt=False,
precision="fp32",
cpu_threads=10,
enable_mkldnn=False):
self.max_seq_length = max_seq_length
self.batch_size = batch_size
model_file = model_dir + "/inference.get_pooled_embedding.pdmodel"
params_file = model_dir + "/inference.get_pooled_embedding.pdiparams"
if not os.path.exists(model_file):
raise ValueError("not find model file path {}".format(model_file))
if not os.path.exists(params_file):
raise ValueError("not find params file path {}".format(params_file))
config = paddle.inference.Config(model_file, params_file)
if device == "gpu":
# set GPU configs accordingly
# such as intialize the gpu memory, enable tensorrt
config.enable_use_gpu(100, 0)
precision_map = {
"fp16": inference.PrecisionType.Half,
"fp32": inference.PrecisionType.Float32,
"int8": inference.PrecisionType.Int8
}
precision_mode = precision_map[precision]
if use_tensorrt:
config.enable_tensorrt_engine(
max_batch_size=batch_size,
min_subgraph_size=30,
precision_mode=precision_mode)
elif device == "cpu":
# set CPU configs accordingly,
# such as enable_mkldnn, set_cpu_math_library_num_threads
config.disable_gpu()
if args.enable_mkldnn:
# cache 10 different shapes for mkldnn to avoid memory leak
config.set_mkldnn_cache_capacity(10)
config.enable_mkldnn()
config.set_cpu_math_library_num_threads(args.cpu_threads)
elif device == "xpu":
# set XPU configs accordingly
config.enable_xpu(100)
config.switch_use_feed_fetch_ops(False)
self.predictor = paddle.inference.create_predictor(config)
self.input_handles = [
self.predictor.get_input_handle(name)
for name in self.predictor.get_input_names()
]
self.output_handle = self.predictor.get_output_handle(
self.predictor.get_output_names()[0])
def extract_embedding(self, data, tokenizer):
"""
Predicts the data labels.
Args:
data (obj:`List(str)`): The batch data whose each element is a raw text.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
Returns:
results(obj:`dict`): All the feature vectors.
"""
examples = []
for text in data:
input_ids, segment_ids = convert_example_recall_infer(text, tokenizer)
examples.append((input_ids, segment_ids))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_id), # segment
): fn(samples)
input_ids, segment_ids = batchify_fn(examples)
self.input_handles[0].copy_from_cpu(input_ids)
self.input_handles[1].copy_from_cpu(segment_ids)
self.predictor.run()
logits = self.output_handle.copy_to_cpu()
return logits
def predict(self, data, tokenizer):
"""
Predicts the data labels.
Args:
data (obj:`List(str)`): The batch data whose each element is a raw text.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
Returns:
results(obj:`dict`): All the predictions probs.
"""
examples = []
for idx, text in enumerate(data):
input_ids, segment_ids = convert_example_recall_infer({idx: text[0]}, tokenizer)
title_ids, title_segment_ids = convert_example_recall_infer({
idx: text[1]
}, tokenizer)
examples.append(
(input_ids, segment_ids, title_ids, title_segment_ids))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_id), # segment
Pad(axis=0, pad_val=tokenizer.pad_token_id), # segment
Pad(axis=0, pad_val=tokenizer.pad_token_id), # segment
): fn(samples)
query_ids, query_segment_ids, title_ids, title_segment_ids = batchify_fn(
examples)
self.input_handles[0].copy_from_cpu(query_ids)
self.input_handles[1].copy_from_cpu(query_segment_ids)
self.predictor.run()
query_logits = self.output_handle.copy_to_cpu()
self.input_handles[0].copy_from_cpu(title_ids)
self.input_handles[1].copy_from_cpu(title_segment_ids)
self.predictor.run()
title_logits = self.output_handle.copy_to_cpu()
result = [
float(1 - spatial.distance.cosine(arr1, arr2))
for arr1, arr2 in zip(query_logits, title_logits)
]
return resultmodel_dir = 'output/recall'
device='gpu'
max_seq_length=64
use_tensorrt = False
batch_size =32
precision = 'fp32'
cpu_threads = 1
enable_mkldnn =False
predictor = RecallPredictor(model_dir, device, max_seq_length,
batch_size, use_tensorrt, precision,
cpu_threads, enable_mkldnn)
id2corpus = {0: '国有企业引入非国有资本对创新绩效的影响——基于制造业国有上市公司的经验证据'}
corpus_list = [{idx: text} for idx, text in id2corpus.items()]
res = predictor.extract_embedding(corpus_list, tokenizer)
print('抽取向量')
print(res.shape)
print(res)
corpus_list = [['中西方语言与���化的差异', '中西方文化差异以及语言体现中西方文化,差异,语言体现'],
['中西方语言与文化的差异', '飞桨致力于让深度学习技术的创新与应用更简单']]
res = predictor.predict(corpus_list, tokenizer)
print('计算相似度')
print(res)导出静态图接下来就是部署了,目前部署支持C++和Pipeline两种方式,由于aistudio不支持部署环境,需要部署的话可以参考链接:[https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/neural_search/recall/in_batch_negative/deploy](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/neural_search/recall/in_batch_negative/deploy)
### 基于Milvus的效果展示
在实际上线中,我们需要使用向量检索引擎,由于aistudio不支持搭建Milvus,有条件的同学可以本地搭建一个,使用Docker安装。
#### 基于Milvus搭建召回服务
我们使用[Milvus](https://milvus.io/)开源工具进行召回,milvus的搭建教程��参考官方教程 [milvus官方安装教程](https://milvus.io/cn/docs/v1.1.1/milvus_docker-cpu.md)本案例使用的是milvus的1.1.1版本,搭建完以后启动milvuscd [Milvus root path]/core/milvus
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:[Milvus root path]/core/milvus/lib
cd scripts
./start_server.sh
#### 基于Milvus的召回效果展示 输入的样本为:
国有企业引入非国有资本对创新绩效的影响——基于制造业国有上市公司的经验证据
下面分别是抽取的向量和召回的结果:
[1, 256]
[[ 0.06374735 -0.08051944 0.05118101 -0.05855767 -0.06969483 0.05318566
0.079629 0.02667932 -0.04501902 -0.01187392 0.09590752 -0.05831281
…
5677638 国有股权参股对家族企业创新投入的影响混合所有制改革,国有股权,家族企业,创新投入 0.5417419672012329
1321645 高管政治联系对民营企业创新绩效的影响——董事会治理行为的非线性中介效应高管政治联系,创新绩效,民营上市公司,董事会治理行为,中介效应 0.5445536375045776
1340319 国有控股上市公司资产并购重组风险探讨国有控股上市公司,并购重组,防范对策 0.5515031218528748
…
上述流程就是召回的全流程,如果对精度要求不高或者数据量不高,可以完全使用召回模型得到的结果。如果数据量比较大,或者有多路召回的结果,则需要下面的排序方案,排序的作用就是对召回的结果进行重排,使得结果更加精确。## 四、排序方案实践 ### 方案简介 基于ERNIE-Gram训练Pair-wise模型。Pair-wise 匹配模型适合将文本对相似度作为特征之一输入到上层排序模块进行排序的应用场景。 双塔模型,使用ERNIE-Gram预训练模型,使用margin_ranking_loss训练模型。 ### 数据准备 使用点击(作为正样本)和展现未点击(作为负样本)数据构造排序阶段的训练集 样例数据如下:
个人所得税税务筹划 基于��个税视角下的个人所得税纳税筹划分析新个税;个人所得税;纳税筹划 个人所得税工资薪金税务筹划研究个人所得税,工资薪金,税务筹划
液压支架底座受力分析 ZY4000/09/19D型液压支架的有限元分析液压支架,有限元分析,两端加载,偏载,扭转 基于ANSYS的液压支架多工况受力分析液压支架,四种工况,仿真分析,ANSYS,应力集中,优化
迟发性血管痉挛 西洛他唑治疗动脉瘤性蛛网膜下腔出血后脑血管痉挛的meta分析西洛他唑,蛛网膜下腔出血,脑血管痉挛,meta分析 西洛他唑治疗动脉瘤性蛛网膜下腔出血后脑血管痉挛的meta分析西洛他唑,蛛网膜下腔出血,脑血管痉挛,meta分析
氧化亚硅 复合溶胶-凝胶一锅法制备锂离子电池氧化亚硅/碳复合负极材料氧化亚硅,溶胶-凝胶法,纳米颗粒,负极,锂离子电池 负载型聚酰亚胺-二氧化硅-银杂化膜的制备和表征聚酰亚胺,二氧化硅,银,杂化膜,促进传输
# 构建读取函数,读取原始数据
def read(src_path, is_predict=False):
data=pd.read_csv(src_path,sep='\t')
for index, row in tqdm(data.iterrows()):
query=row['query']
title=row['title']
neg_title=row['neg_title']
yield {'query':query, 'title':title,'neg_title':neg_title}
def read_test(src_path, is_predict=False):
data=pd.read_csv(src_path,sep='\t')
for index, row in tqdm(data.iterrows()):
query=row['query']
title=row['title']
label=row['label']
yield {'query':query, 'title':title,'label':label}
test_file='dev_ranking_demo.csv'
train_file='train_ranking_demo.csv'
train_ds=load_dataset(read,src_path=train_file,lazy=False)
dev_ds=load_dataset(read_test,src_path=test_file,lazy=False)
print('打印一条训练集')
print(train_ds[0])
print('打印一条验证集')
print(dev_ds[0])### 模型构建
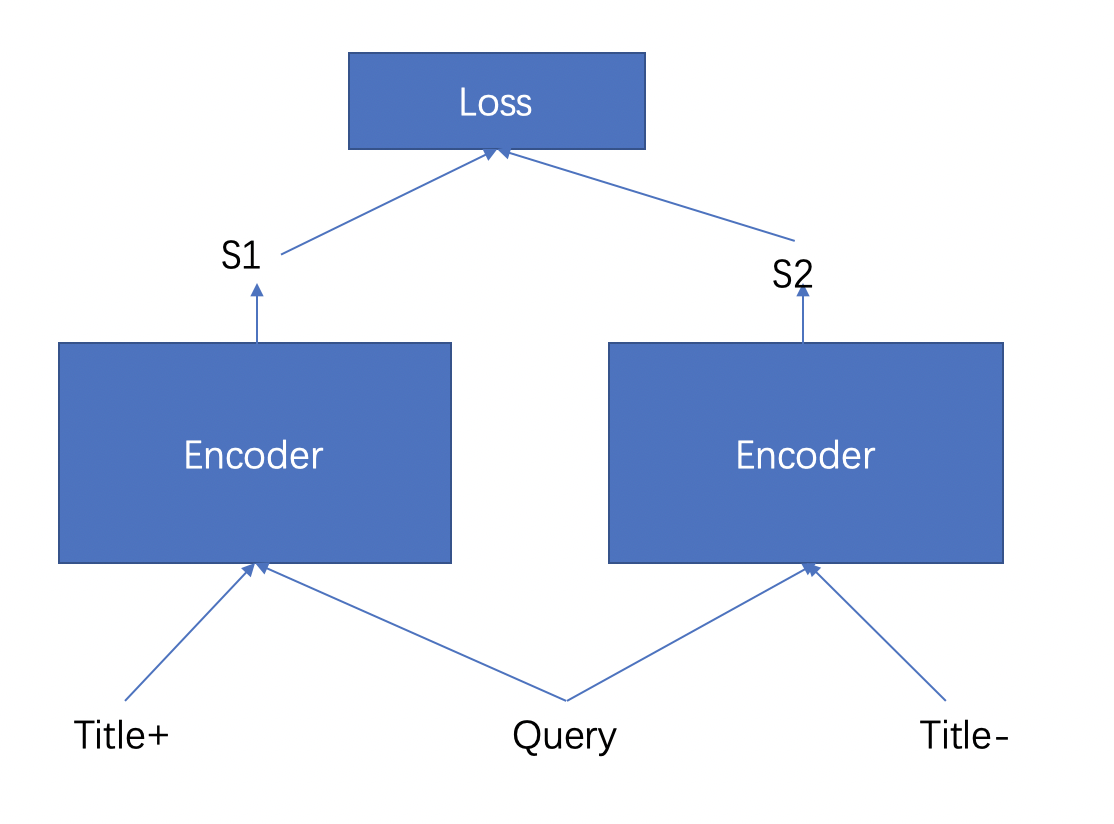
排序模型是pair-wise的结构,如图所示,query和titile正样本会经过encoder得到一个输出的相似度S1,query和title负样本也会经过Encoder得到一个输出的相似度S2,然后模型根据S1和S2求Triplet损失,其中S1的相似度要大于S2。
比如:对于文本:个人所得税税务筹划 基于新个税视角下的个人所得税纳税筹划分析新个税;个人所得税;纳税筹划 个人所得税工资薪金税务筹划研究个人所得税,工资薪金,税务筹划
最终构造出来一条正样本对和一条负样本对,如下:
正样本对:[CLS]个人所得税税务筹划[SEP]基于新个税视角下的个人所得税纳税筹划分析新个税;个人所得税;纳税筹划[SEP]
负样本对:[CLS]个人所得税税务筹划[SEP]个人所得税工资薪金税务筹划研究个人所得税,工资薪金,税务筹划[SEP]
def __init__(self, pretrained_model, dropout=None, margin=0.1):
super().__init__()
self.ptm = pretrained_model
self.dropout = nn.Dropout(dropout if dropout is not None else 0.1)
self.margin = margin
# hidden_size -> 1, calculate similarity
self.similarity = nn.Linear(self.ptm.config["hidden_size"], 1)
# 用于导出静态图模型来计算概率
@paddle.jit.to_static(input_spec=[paddle.static.InputSpec(shape=[None, None], dtype='int64'),paddle.static.InputSpec(shape=[None, None], dtype='int64')])
def get_pooled_embedding(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
_, cls_embedding = self.ptm(input_ids, token_type_ids,
position_ids, attention_mask)
cls_embedding = self.dropout(cls_embedding)
# 计算相似度
sim = self.similarity(cls_embedding)
return sim
def predict(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
_, cls_embedding = self.ptm(input_ids, token_type_ids, position_ids,
attention_mask)
cls_embedding = self.dropout(cls_embedding)
sim_score = self.similarity(cls_embedding)
sim_score = F.sigmoid(sim_score)
return sim_score
def forward(self,
pos_input_ids,
neg_input_ids,
pos_token_type_ids=None,
neg_token_type_ids=None,
pos_position_ids=None,
neg_position_ids=None,
pos_attention_mask=None,
neg_attention_mask=None):
_, pos_cls_embedding = self.ptm(pos_input_ids, pos_token_type_ids,
pos_position_ids, pos_attention_mask)
_, neg_cls_embedding = self.ptm(neg_input_ids, neg_token_type_ids,
neg_position_ids, neg_attention_mask)
pos_embedding = self.dropout(pos_cls_embedding)
neg_embedding = self.dropout(neg_cls_embedding)
pos_sim = self.similarity(pos_embedding)
neg_sim = self.similarity(neg_embedding)
pos_sim = F.sigmoid(pos_sim)
neg_sim = F.sigmoid(neg_sim)
labels = paddle.full(
shape=[pos_cls_embedding.shape[0]], fill_value=1.0, dtype='float32')
loss = F.margin_ranking_loss(
pos_sim, neg_sim, labels, margin=self.margin)
return loss### 训练配置
配置模型所需要的一些超参数,实例化模型,优化器等等。# 关键参数
margin=0.2 # 推荐取值 0.0 ~ 0.2
eval_step=100
max_seq_length=128
epochs=3
batch_size=32
warmup_proportion=0.0
weight_decay=0.0
save_step=100#### 加载预训练模型 ERNIG-Gram
基于 ERNIE-Gram 热启训练单塔 Pair-wise 排序模型,并定义数据读取的 DataLoaderpretrained_model = ppnlp.transformers.ErnieGramModel.from_pretrained(
'ernie-gram-zh')
tokenizer = ppnlp.transformers.ErnieGramTokenizer.from_pretrained(
'ernie-gram-zh')
trans_func_train = partial(
convert_pairwise_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
trans_func_eval = partial(
convert_pairwise_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
phase="eval")
batchify_fn_train = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # pos_pair_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # pos_pair_segment
Pad(axis=0, pad_val=tokenizer.pad_token_id), # neg_pair_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id) # neg_pair_segment
): [data for data in fn(samples)]
batchify_fn_eval = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # pair_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # pair_segment
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn_train,
trans_fn=trans_func_train)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn_eval,
trans_fn=trans_func_eval)
model = PairwiseMatching(pretrained_model, margin=margin)# 打印训练集的batch数据
for item in train_data_loader:
print(item)
break
# 打印验证集的batch数据
for item in dev_data_loader:
print(item)
break训练集的数据包含4个Tensor,分别表示的是query和正样本title的input_ids和token_type_ids,以及query和负样本title的input_ids和token_type_ids。
验证集则不一样,包含3个Tensor,除了了query后天title拼接成的input_id和token_type_ids的形式为,还有label,表明这条query和title是否相似,1表示的是相似,0表示的是不相似。### 模型训练
下面是模型训练过程,由于在训练的时候使用了评估,所以先构建评估函数。@paddle.no_grad()
def evaluate(model, metric, data_loader, phase="dev"):
model.eval()
metric.reset()
for idx, batch in enumerate(data_loader):
input_ids, token_type_ids, labels = batch
# 类别为正的概率
pos_probs = model.predict(input_ids=input_ids, token_type_ids=token_type_ids)
# 类别为负的概率
neg_probs = 1.0 - pos_probs
preds = np.concatenate((neg_probs, pos_probs), axis=1)
metric.update(preds=preds, labels=labels)
print("eval_{} auc:{:.3}".format(phase, metric.accumulate()))
metric.reset()
model.train()下面是排序模型的训练过程。def do_train(model,train_data_loader,dev_data_loader):
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps,
warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
# 使用AUC作为评估指标
metric = paddle.metric.Auc()
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
pos_input_ids, pos_token_type_ids, neg_input_ids, neg_token_type_ids = batch
loss = model(
pos_input_ids=pos_input_ids,
neg_input_ids=neg_input_ids,
pos_token_type_ids=pos_token_type_ids,
neg_token_type_ids=neg_token_type_ids)
# 每隔10个step打印日志
global_step += 1
if global_step % 10 == 0 :
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向求梯度
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
# 每隔eval_step进行评估
if global_step % eval_step == 0:
evaluate(model, metric, dev_data_loader, "dev")
# 每隔save_steps保存模型
if global_step % save_step == 0:
save_path = os.path.join(save_dir, "model_%d" % global_step)
if not os.path.exists(save_path):
os.makedirs(save_path)
save_param_path = os.path.join(save_path, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_path)
do_train(model,train_data_loader,dev_data_loader)
### 效果评估
下面是效果评估,首先下载训练好的预训练模型,然后进行解压。# !wget https://bj.bcebos.com/v1/paddlenlp/models/ernie_gram_sort.zip
if(not os.path.exists('ernie_gram_sort.zip')):
get_path_from_url('https://bj.bcebos.com/v1/paddlenlp/models/ernie_gram_sort.zip',root_dir='.')
!unzip -o ernie_gram_sort.zip -d pretrained/加载训练好的模型,进行评估。init_from_ckpt='pretrained/model_30000/model_state.pdparams'
state_dict = paddle.load(init_from_ckpt)
model.set_dict(state_dict)
metric = paddle.metric.Auc()
evaluate(model, metric, dev_data_loader, "dev")排序模块用的指标是AUC,随机抽出一对样本,用训练得到的分类起来对两个样本进行预测,预测得到正样本概率>负样本的概率的概率。 一般AUC达到0.7以上就算是不错的,但也要根据任务场景进行分析,有的可能连0.7也达不到,但是效果也是非常不错的。### 模型推理
from data import read_text_pair
input_file='test_pairwise.csv'
valid_ds = load_dataset(read_text_pair, data_path=input_file, lazy=False)
# 打印一条数据
print(valid_ds[0])trans_func = partial(
convert_pairwise_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
phase="predict")
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment_ids
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
valid_ds,
mode='predict',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# 打印测试的样本
for item in test_data_loader:
print(item)
breakdef predict(model, data_loader):
batch_probs = []
model.eval()
with paddle.no_grad():
for batch_data in data_loader:
input_ids, token_type_ids = batch_data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
# 输入query title pair得到预测的概率
batch_prob = model.predict(
input_ids=input_ids, token_type_ids=token_type_ids).numpy()
batch_probs.append(batch_prob)
if(len(batch_prob)==1):
batch_probs=np.array(batch_probs)
else:
batch_probs = np.concatenate(batch_probs, axis=0)
return batch_probs
y_probs = predict(model, test_data_loader)
valid_ds = load_dataset(read_text_pair, data_path=input_file, lazy=False)
# 打印输出
for idx, prob in enumerate(y_probs):
text_pair = valid_ds[idx]
text_pair["pred_prob"] = prob[0]
print(text_pair)### 预测部署
首先把动态图模型转换成静态图模型。output_path='output/rank'
model.eval()
# Convert to static graph with specific input description
model = paddle.jit.to_static(
model,
input_spec=[
paddle.static.InputSpec(
shape=[None, None], dtype="int64"), # input_ids
paddle.static.InputSpec(
shape=[None, None], dtype="int64") # segment_ids
])
# Save in static graph model.
save_path = os.path.join(output_path, "inference")
paddle.jit.save(model, save_path)定义Predictor用于加载静态图的模型参数进行预测。class Predictor(object):
def __init__(self,
model_dir,
device="gpu",
max_seq_length=128,
batch_size=32,
use_tensorrt=False,
precision="fp32",
cpu_threads=10,
enable_mkldnn=False):
self.max_seq_length = max_seq_length
self.batch_size = batch_size
model_file = model_dir + "/inference.get_pooled_embedding.pdmodel"
params_file = model_dir + "/inference.get_pooled_embedding.pdiparams"
if not os.path.exists(model_file):
raise ValueError("not find model file path {}".format(model_file))
if not os.path.exists(params_file):
raise ValueError("not find params file path {}".format(params_file))
config = paddle.inference.Config(model_file, params_file)
if device == "gpu":
# set GPU configs accordingly
# such as intialize the gpu memory, enable tensorrt
config.enable_use_gpu(100, 0)
precision_map = {
"fp16": inference.PrecisionType.Half,
"fp32": inference.PrecisionType.Float32,
"int8": inference.PrecisionType.Int8
}
precision_mode = precision_map[precision]
if use_tensorrt:
config.enable_tensorrt_engine(
max_batch_size=batch_size,
min_subgraph_size=30,
precision_mode=precision_mode)
elif device == "cpu":
# set CPU configs accordingly,
# such as enable_mkldnn, set_cpu_math_library_num_threads
config.disable_gpu()
if enable_mkldnn:
# cache 10 different shapes for mkldnn to avoid memory leak
config.set_mkldnn_cache_capacity(10)
config.enable_mkldnn()
config.set_cpu_math_library_num_threads(cpu_threads)
elif device == "xpu":
# set XPU configs accordingly
config.enable_xpu(100)
config.switch_use_feed_fetch_ops(False)
self.predictor = paddle.inference.create_predictor(config)
self.input_handles = [
self.predictor.get_input_handle(name)
for name in self.predictor.get_input_names()
]
self.output_handle = self.predictor.get_output_handle(
self.predictor.get_output_names()[0])
def predict(self, data, tokenizer):
examples = []
for text in data:
input_ids, segment_ids = convert_example_ranking(
text,
tokenizer,
max_seq_length=self.max_seq_length,
is_test=True)
examples.append((input_ids, segment_ids))
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_id), # segment
): fn(samples)
input_ids, segment_ids = batchify_fn(examples)
self.input_handles[0].copy_from_cpu(input_ids)
self.input_handles[1].copy_from_cpu(segment_ids)
self.predictor.run()
sim_score = self.output_handle.copy_to_cpu()
sim_score = expit(sim_score)
return sim_score读取测试集的文本,把文本利用convert_example_ranking函数转换成id向量的形式。def convert_example_ranking(example, tokenizer, max_seq_length=512, is_test=False):
query, title = example["query"], example["title"]
encoded_inputs = tokenizer(
text=query, text_pair=title, max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
input_file='test_pairwise.csv'
test_ds = load_dataset(read_text_pair,data_path=input_file, lazy=False)
data = [{'query': d['query'], 'title': d['title']} for d in test_ds]
batches = [
data[idx:idx + batch_size]
for idx in range(0, len(data), batch_size)
]
print(batches[0])实例化Predictor,然后进行预测。model_dir='output/rank'
device='gpu'
max_seq_length=128
batch_size=32
# 可以安装对应的Tensorrt之后进行加速
use_tensorrt=False
# 精度,也可以选择fp16,精度几乎无损
precision='fp32'
# cpu的线程数目
cpu_threads=10
# 可以在CPU的情况下进行加速
enable_mkldnn=False
predictor = Predictor(model_dir, device, max_seq_length,
batch_size, use_tensorrt, precision,
cpu_threads, enable_mkldnn)
results = []
for batch_data in batches:
results.extend(predictor.predict(batch_data, tokenizer))
for idx, text in enumerate(data):
print('data: {} \t prob: {}'.format(text, results[idx]))
# 东西太多,需要删除一下
! rm -rf output/
! rm -rf checkpoint/# 五、参考文献
[1] Tianyu Gao, Xingcheng Yao, Danqi Chen: [SimCSE: Simple Contrastive Learning of Sentence Embeddings](https://arxiv.org/abs/2104.08821). EMNLP (1) 2021: 6894-6910
[2] Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih, [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906). Preprint 2020.
[3] Dongling Xiao, Yu-Kun Li, Han Zhang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang:
[ERNIE-Gram: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding](https://arxiv.org/abs/2010.12148). NAACL-HLT 2021: 1702-1715
[4] Yu Sun, Shuohuan Wang, Yu-Kun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu:
[ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223). CoRR abs/1904.09223 (2019)## 加入微信交流群,一起学习吧
现在就加入PaddleNLP的技术交流群(微信),一起交流NLP技术吧!
<img src="https://user-images.githubusercontent.com/11793384/148375398-f9a1b4db-66ba-4325-8a1d-abfc47780c7c.png" width="200" height="200" >

 微信联系
微信联系
