1 项目说明
随着UGC视频的爆炸增长,短视频人均使用时长及头部短视频平台日均活跃用户均持续增长,内容消费的诉求越来越受到人们的重视。同时对视频内容的理解丰富度要求也越来越高,需要对视频所带文本、音频、图像多模态数据多角度理解,才能提炼出用户真实的兴趣点和高层次语义信息。目前存在以下挑战:
标签高语义
模态不对齐
多模态语义鸿沟
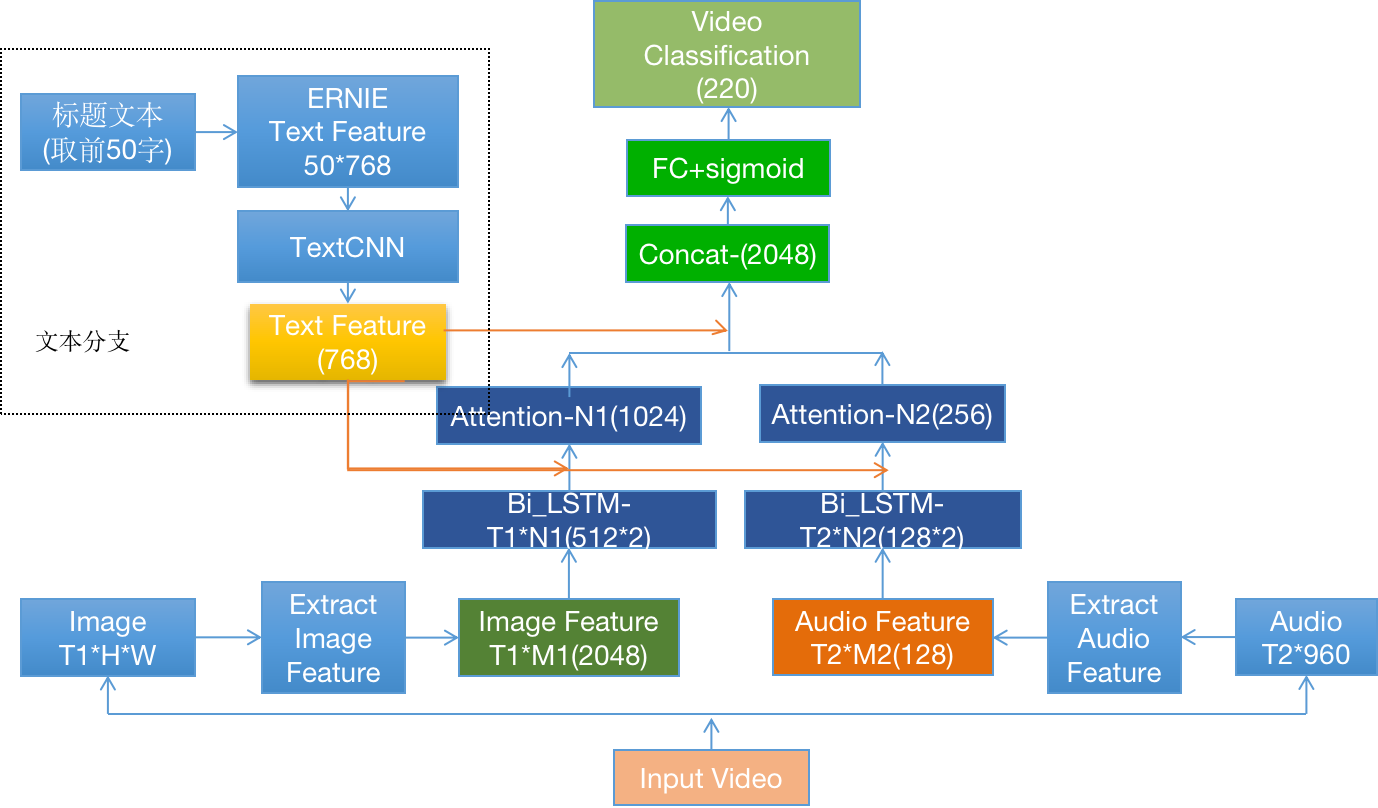
我们使用MutimodalVideoTag多模态视频分类模型,基于Paddle2.0版本进行开发。模型基于真实短视频业务数据,融合文本、视频图像、音频三种模态进行视频多模标签分类,相比纯视频图像特征,显著提升高层语义标签效果。其原理示意如 **图1 **所示。
欢迎报名直播课加入交流群,如需更多技术交流与合作可点击报名链接
2 安装说明
环境要求
PaddlePaddle>=2.0.0
Python >= 3.5
下载PaddleVideo源码,下载一次即可:
!git clone https://github.com/PaddlePaddle/PaddleVideo.git* 注:更多安装教程请参考安装教程
3 数据准备
数据源来自UGC用户制作上传客户视频和视频标题,分别对视频三个模态的数据进行处理,对视频进行抽帧,获得图像序列;抽取视频的音频pcm文件;收集视频标题,简单进行文本长度截断,一般取50个字。
本项目提供已经抽取好图像、音频特征的特征文件,以及标题和标签信息,模型方面提供训练好checkpoint 文件,可进行finetune、模型评估、预测。执行如下命令即可下载,数据下载一次即可。%cd /home/aistudio/PaddleVideo/applications/MultimodalVideoTag/!sh download.sh下载的数据文件包括抽取好特征的文件夹feature_files,以及记录划分的txt 文件。其中feature_files包含了特征文件,格式为pkl,我们通过读取pkl文件查看存储结构。import pickle
import numpy as np
record = pickle.load(open(‘datasets/feature_files/74f021eb0d34ac98bc47837f9cbc5afa.pkl’, ‘rb’))
print(record.keys())
print('video feature: ', np.array(record[‘feature’][‘image_pkl’]).shape)
print('audio feature: ', np.array(record[‘feature’][‘audio_pkl’]).shape)
print('label: ', record[‘label’])记录划分的txt 文件格式如下:
文件名 \t 标题 \t 标签 18e9bf08a2fc7eaa4ee9215ab42ea827.mp4 叮叮来自肖宇梁肖宇梁rainco的特别起床铃声 拍人-帅哥,拍人-秀特效,明星周边-其他明星周边
我们可以通过head命令展示几条数据。
!head -n 10 datasets/val.txt# 标签文件
!head -n 10 datasets/class.txt
4 模型训练
模型训练整体流程如图2 所示,
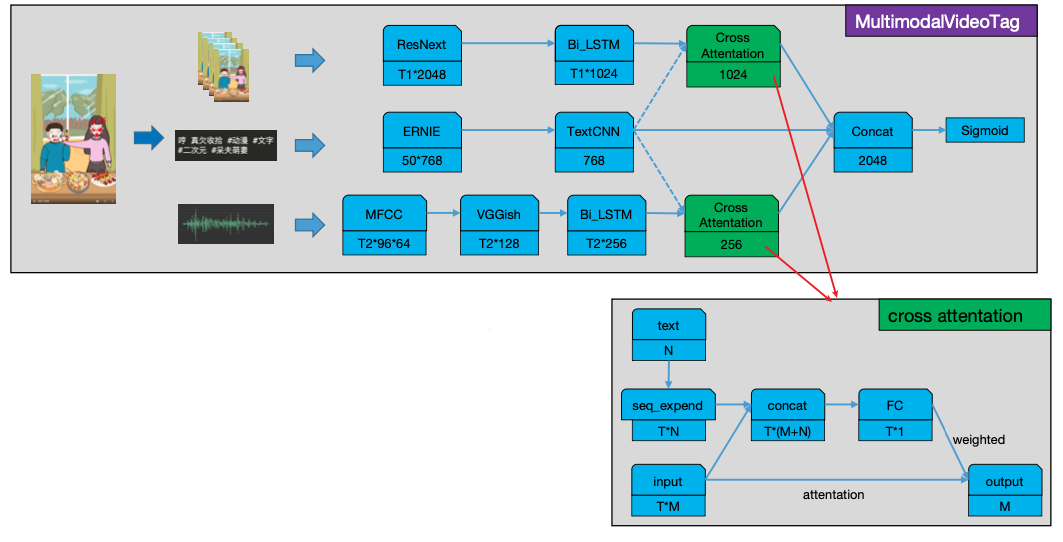
包含以下几个步骤:
特征抽取:使用预训练的 ResNet 对图像抽取高层语义特征;使用预训练的VGGish网络抽取音频特征;文本方面使用ERNIE 1.0抽取文本特征,无需预先抽取,支持视频分类模型finetune
序列学习:分别使用独立的LSTM 对图像特征和音频特征进行序列学习,文本方面预训练模型对字符序列进行建模,在ernie 后接入一个textcnn 网络做下游任务的迁移学习。
多模融合:文本具有显式的高层语义信息,将文本特征引入到LSTM pooling 过程指导图像和音频时序权重分配,进行交叉融合,最后将文本、音频、视频特征拼接。
预测结果:分类器选用sigmoid 多标签分类器,支持视频多标签输出。
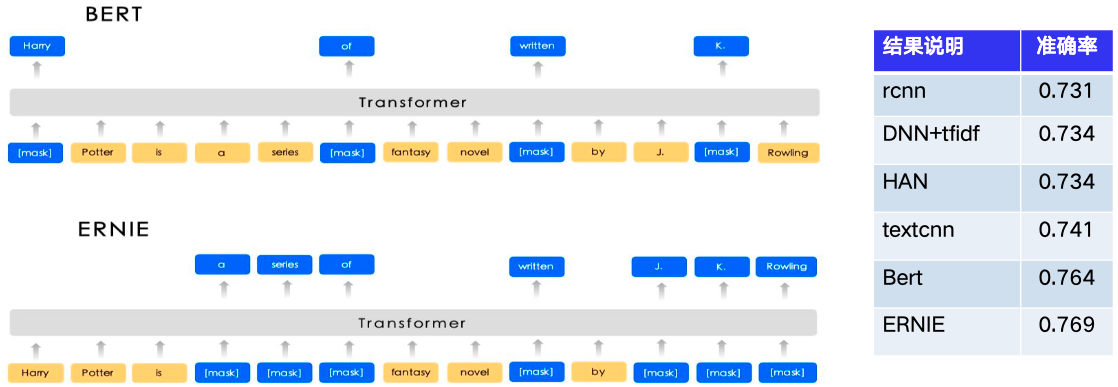
文本特征提取
纯短文本分类,仅使用视频文本情况下(这里来自视频标题),评估多种文本编码器的分类效果,基于预训练模型的Bert和ERNIE有较大优势。
图像特征提取
对视频进行截帧,每帧图像特征取自训练好的图像实体分类特征层,即分类前的隐层向量2048维, 作为图像的高语义向量表示,图像实体分类在千万规模、1000+类别图片上使用RestNet 进行训练。
音频特征提取
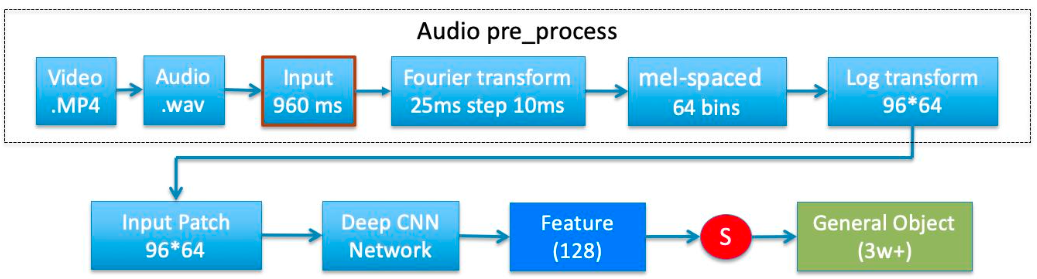
对视频抽取音频wav文件,整个音频文件以960ms分段,每个960ms作为一个分段抽取128纬特征,960ms内部以窗口大小25ms,步长大小10ms ,通过mel + log传统音频特征抽取,抽取96* 64的音频特征,把这个特征当做一幅长度96,宽度64的图输入到VGGish 深度CNN 网络提取128纬特征向量,该网络使用Audioset(大规模音频分类数据集) 进行预训练。
多模态融合
融合图像、音频、文本 三种模态特征,图像和音频为时间可对齐的序列特征,而和文本的序列非对齐, 结合UGC 视频主题杂乱的特点,将文本特征融入到音频、文本的时序attention中,增强文本和特定视频 帧、音频特征的匹配作用。也尝试基于门控的GMU方法,利用门控分别对每个模态控制,最后模态叠加。
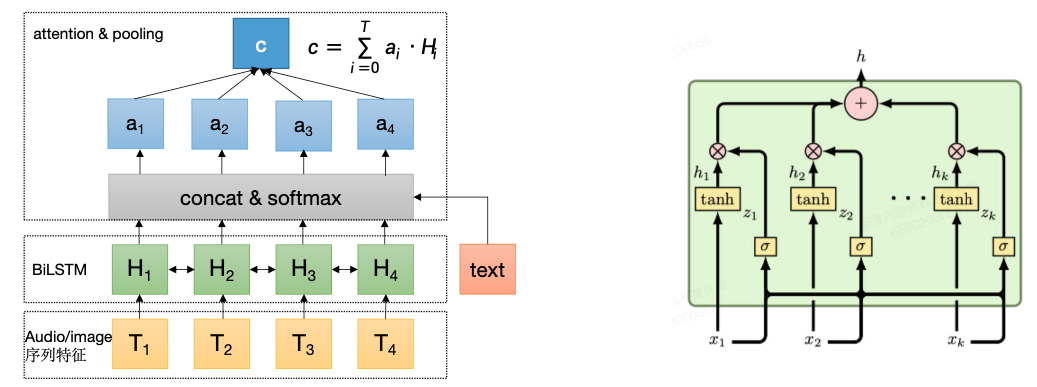
模型训练过程有如下可调模式,可在根据数据集情况进行调整,在conf/conf.txt 文件中
ernie_freeze: 用于控制文本提特征的ernie 网络是否进行finetune,因为ernie 复杂度远大于图像、视频序列学习网络,因此在某些数据集上不好训练。
lstm_pool_mode: 用于控制lstm 序列池化的方式,默认是"text_guide"表示利用文本加强池化注意力权重,如果设置为空,则默认为自注意力的权重。
执行如下命令启动训练即可。%cd /home/aistudio/PaddleVideo/applications/MultimodalVideoTag/
!sh train.sh
5 模型评估
模型对测试集进行评估,同时支持将checkpoint 模型转为inference 模型, 可用参数’save_only’
选项控制,设置即只用于做模型转换,得到inference 模型,输出结果第一行表示loss,第二行表示Hit@1 acc指标。!sh
eval_and_save_model.sh!ls checkpoints_save_new/# 选择最优模型进行预测
!python scenario_lib/eval_and_save_model.py --model_name=AttentionLstmErnie
–config=./conf/conf.txt
–save_model_param_dir=checkpoints_save_new/AttentionLstmErnie_epoch4_acc100.0
–save_inference_model=inference_models_save
6 模型推理
通过上一步得到的inference 模型进行预测,结果默认阈值为0.5,存储到json 文件中,在conf/conf.txt 文件 threshold 参数进行控制多标签输出的阈值。!sh inference.sh查看推理结果,"video_id"表示测试的视频,"labels"分别表示预测类型和置信度。! head -n 10 output.json
7 模型优化
主要在文本分支进行了实验,首先加入文本对模型效果有明显提升,实验结果显示ERNIE 在多分支下不 微调,而是使用后置网络进行微调,训练速度快,且稳定,同时attention 方面使用文本信息增强图像、 音频的attention 学习能一定程度提升模型效果。
| 模型 | Hit@1 | Hit@2 |
|---|---|---|
| 图像+音频 | 63 | 78 |
| 图像+音频+文本分支ERNIE 不finetune +self-attention | 71.07 | 83.72 |
| 图像+音频+文本分支ERNIE 不finetune +textcnn finetune + self-attention | 72.66 | 85.01 |
| 图像+音频+文本分支ERNIE 不finetune +textcnn finetune + text-guide-attention | 73.29 | 85.59 |
这里对多模融合方式进行实验,可以看到在同样没有拼接文本特征的情况下,使用文本进行指导video 和 audio 的 pooling 过程,仅仅只是贡献了LSTM pooling 的attention 权重,显著提升了模型效果+2.6%, 证明文本还是可以和图像,音频产生语义对齐的关系。下图为 attention 权重在时间上分布。
| 模型 | Hit@1 | Hit@2 |
|---|---|---|
| 图像+音频 | 63 | 78 |
| 图像+音频+text-guide-attention | 66 | 80.5 |
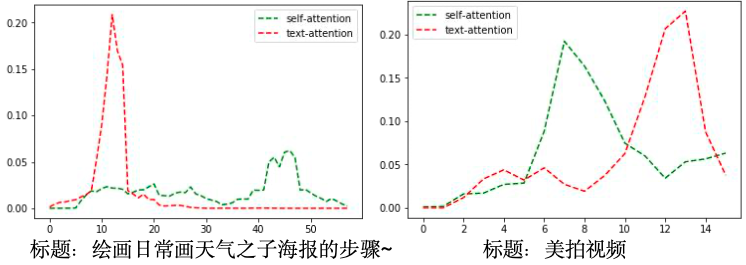
模型鲁棒性,标题信息是不可控的,为了应对标题缺失的情况,这里的目标是不带标题信息,起 码应该达到video + audio 的效果,实验发现以整体概率置空效果较好,实验阈值整体概率值为 0.4时达到最佳。
| 模型 | 预测不带标题Hit@1 | 带标题Hit@1 | 带标题Hit@2 |
|---|---|---|---|
| 图像+音频 | 63 | 63 | 78 |
| 图像+音频+文本 | 55 | 73.3 | 85.6 |
| 图像+音频+随机0.4 drop | 62 | 72.4 | 85.1 |
8 模型部署
在项目中为用户提供了基于paddle inference C++ 按照部署的方案,效果如下所示。用户可根据实际情况自行参考。
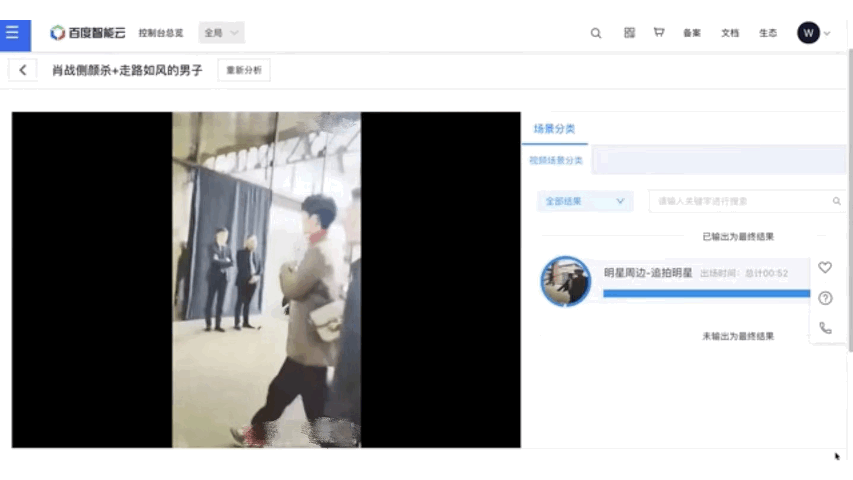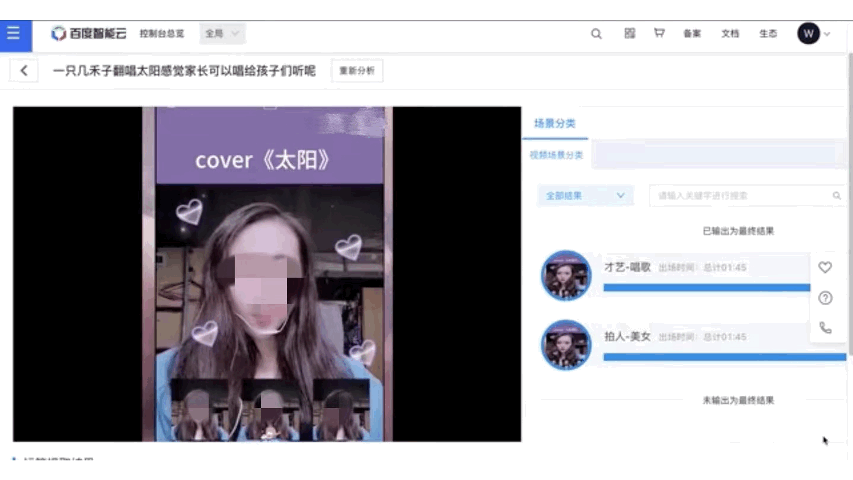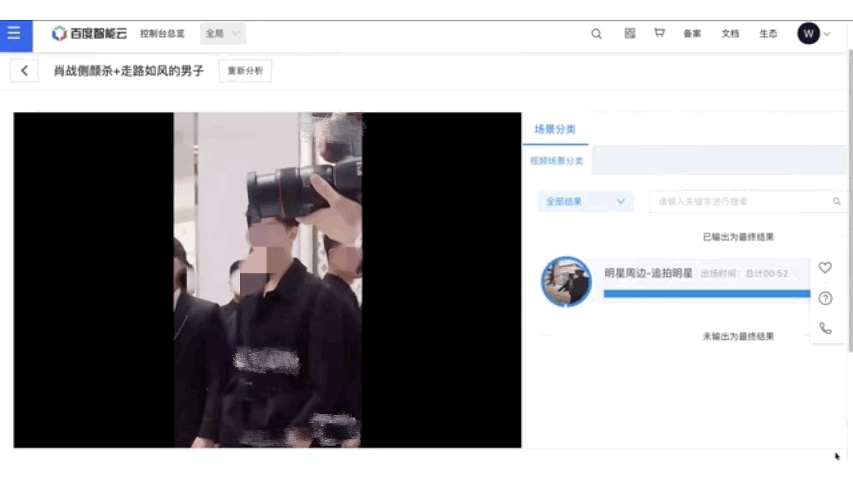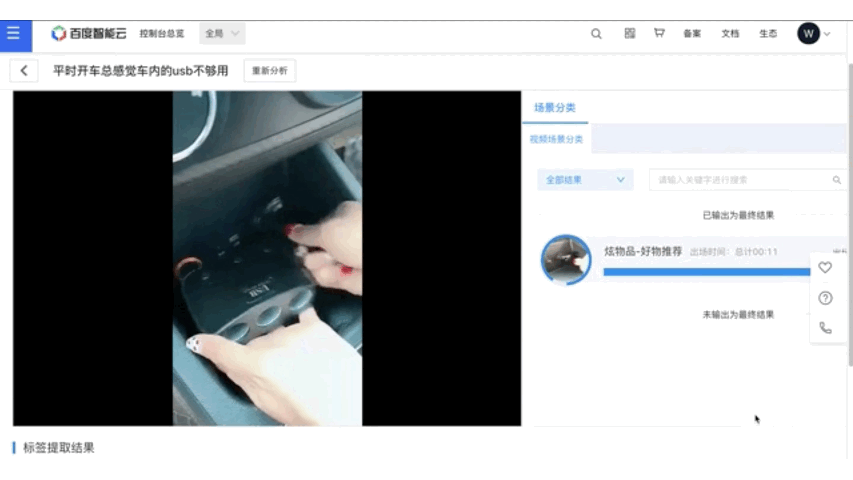
欢迎报名直播课加入交流群,如需更多技术交流与合作可点击报名链接# 参考论文
Attention Clusters: Purely Attention based Local Feature Integration for Video Classification, Xiang Long, Chuang Gan, Gerard de Melo, Jiajun Wu, Xiao Liu, Shilei Wen
YouTube-8M: A Large-Scale Video Classification Benchmark, Sami Abu-El-Haija, Nisarg Kothari, Joonseok Lee, Paul Natsev, George Toderici, Balakrishnan Varadarajan, Sudheendra Vijayanarasimhan
Ernie: Enhanced representation through knowledge integration, Sun, Yu and Wang, Shuohuan and Li, Yukun and Feng, Shikun and Chen, Xuyi and Zhang, Han and Tian, Xin and Zhu, Danxiang and Tian, Hao and Wu, Hua
资源
更多资源请参考:
更多深度学习知识、产业案例、面试宝典等,请参考:awesome-DeepLearning
更多PaddleVideo使用教程,请参考:PaddleVideo
飞桨框架相关资料,请参考:飞桨深度学习平台


 微信联系
微信联系
