1. 案例背景
截至2019年底,中国私家车保有量超过200万辆的城市已经超过30个。公安部交通管理局最新统计数据显示,我国汽车保有量达2.87亿辆。交通拥堵、交通安全已经成为“超大城市”的通病。
应用飞桨PaddleDetection的目标跟踪任务可以自动统计交通道路视频的车流量,辅助分析路口、路段的交通状况,为数字城市运营提供数据依据,让每个人的出行都变得安全、高效,模型效果如下图所示。
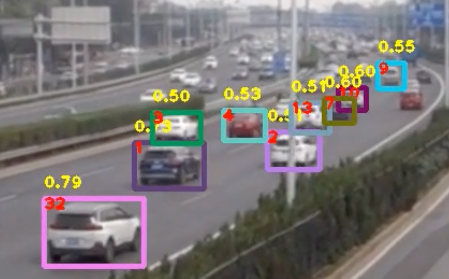
本案例提供从“模型选择→模型优化→模型部署”的全流程指导,模型可以直接或经过少量数据微调后用于相关任务中,无需耗时耗力从头训练。
目标跟踪任务的定义是给定视频流,对多个感兴趣的目标进行同时定位,并且维护个体的ID信息并记录它们的轨迹。
目标跟踪和目标检测任务都能够输出检测信息。对于目标检测,输出一段视频流,输出目标的类别和位置信息,但是视频帧之间没有关联信息,因为目标检测无法对帧与帧进行建模。目标跟踪模型增加了一个目标个体的ID信息,利用目标跟踪模型可以构建出帧与帧之间的联系。两个任务之间的差异点在于目标跟踪需要持续追踪目标运动状态,目标检测只需要检测出目标在某个瞬间的状态即可。
目标跟踪的应用场景有流水线上零件计数、车辆行人计数与轨迹跟踪、医学分析等。
技术难点:
道路环境复杂,容易导致漏检或重识别问题:道路及周边环境复杂,存在车辆在行驶过程中被树木、建筑物或其他车辆遮挡的情况,导致模型漏检或同一辆车在不同时刻被识别成多辆车;
模型推理速度要求高:车辆行驶过程中速度快,实时车辆跟踪对模型推理速度要求较高。
本案例是智慧交通的AI应用-车辆计数与轨迹跟踪,单镜头多车辆追踪计数。
1.1 目标跟踪评估指标
MOTA
MOTA(跟踪准确率),除了误报、丢失目标、ID异常切换情况以外的正确预测样本占所有样本的比率,衡量了跟踪器在检测目标和保持轨迹时的性能,与目标位置的估计精度无关。
MOTP
MOTP(跟踪精确率),默认检测框重合度阈值下正确预测的目标与预测目标总数之比,衡量检测器的定位精度。
IDF1-score
整体评价跟踪器的好坏。
召回率
当IDF1-score最高时正确预测的目标数与真实目标数之比。
IDSW
IDSW衡量跟踪器对于ID切换的程度。该值越低,模型鲁棒性越好。
1.2 部署环境
本案例利用PaddleDetection套件实现。
通过下面的命令解压PaddleDetection代码:
%cd /home/aistudio/work/
! unzip PaddleDetection-mot_feature_model.zip部署环境:%cd /home/aistudio/work/PaddleDetection-mot_feature_model
! pip install -r requirements.txt
! python setup.py install
! pip install pycocotools
1.3 PaddleDetection简介
PaddleDetection飞桨目标检测开发套件,旨在帮助开发者更快更好地完成检测模型的组建、训练、优化及部署等全开发流程。
PaddleDetection模块化地实现了多种主流目标检测算法,提供了丰富的数据增强策略、网络模块组件(如骨干网络)、损失函数等,并集成了模型压缩和跨平台高性能部署能力。
2. 案例数据集
2.1 数据集介绍
本案例利用公开数据集BDD100K,该数据集由伯克利大学AI实验室(BAIR)于2018年5月发布。BDD100K 数据集包含10万段高清视频,每个视频约40秒,720p,30 fps。每个视频的第10秒对关键帧进行采样,得到10万张图片(图片尺寸:1280*720 ),并进行标注。

BDD100K数据集标注如下:
道路目标边界框:10万张图片。其中:训练集7万,测试集2万,验证集1万
可行驶区域:10万张图片
车道线标记:10万张图片
全帧实例分割:1万张图片
Annotation包含了被标记对象的:
源图像的URL、类别标签、大小(起始坐标、结束坐标、宽度和高度)、截断、遮挡和交通灯颜色等信息。
数据集中的GT框标签共有10个类别,分别为:Bus、Light、Sign、Person、Bike、Truck、Motor、Car、Train、Rider。总共约有184万个标定框,不同类型目标的数目统计如下图所示:
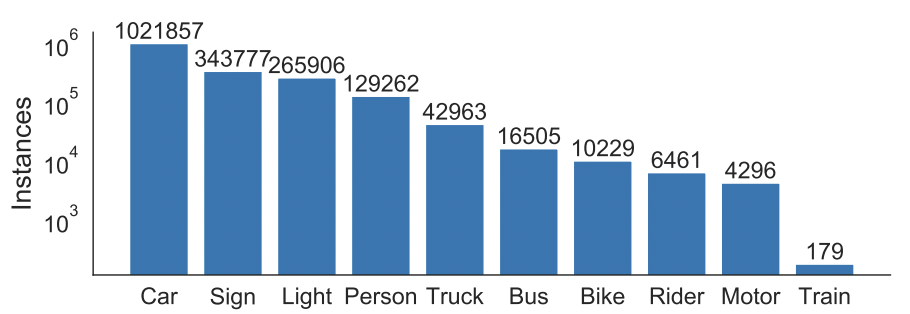
其中汽车(Car)一类超过了100万个样本。
BDD100K数据集采集自6中不同的天气,其中晴天样本较多;采集的场景有6种,以城市街道为主;采集的时间有3个阶段,其中白天和夜晚居多。
本实验会用到BDD100K数据集中所有的四轮车的数据,并且所有的四轮车作为一个类别进行跟踪。
本案例用到的数据是经过处理的,如果需要从源数据开始生成本案例数据,请参考PaddleDetection提供的BDD100K数据处理脚本。
2.2 数据准备
解压数据集:
该过程大约需要1个多小时。
!unzip /home/aistudio/data/data110399/bdd100kmot_vehicle.zip -d /home/aistudio/work/
3. 实现方案
当前主流的多目标追踪(MOT)算法主要由两部分组成:Detection+Embedding。Detection部分即针对视频,检测出每一帧中的潜在目标。Embedding部分则将检出的目标分配和更新到已有的对应轨迹上(即ReID重识别任务)。根据这两部分实现的不同,又可以划分为SDE系列和JDE系列算法。
SDE(Separate Detection and Embedding)这类算法完全分离Detection和Embedding两个环节,最具代表性的就是DeepSORT算法。这样的设计可以使系统无差别的适配各类检测器,可以针对两个部分分别调优,但由于流程上是串联的导致速度慢耗时较长,在构建实时MOT系统中面临较大挑战。
JDE(Joint Detection and Embedding)这类算法完是在一个共享神经网络中同时学习Detection和Embedding,使用一个多任务学习的思路设置损失函数。代表性的算法有JDE和FairMOT。这样的设计兼顾精度和速度,可以实现高精度的实时多目标跟踪。
3.1 方案选择
3.1.1 DeepSort
DeepSORT(Deep Cosine Metric Learning SORT) 扩展了原有的SORT(Simple online and Realtime Tracking)算法,增加了一个CNN模型用于在检测器限定的人体部分图像中提取特征,在深度外观描述的基础上整合外观信息,将检出的目标分配和更新到已有的对应轨迹上即进行一个ReID重识别任务。DeepSORT所需的检测框可以由任意一个检测器来生成,然后读入保存的检测结果和视频图片即可进行跟踪预测。
3.1.2 JDE
JDE(Joint Detection and Embedding)是在一个单一的共享神经网络中同时学习目标检测任务和embedding任务,并同时输出检测结果和对应的外观embedding匹配的算法。JDE原论文是基于Anchor base的YOLOv3检测器新增加一个ReID分支学习embedding,训练过程被构建为一个多任务联合学习问题,兼顾精度和速度。
3.1.3 FairMOT
anchor-based的检测框架中存在anchor和特征的不对齐问题,所以这方面不如anchor-free框架。FairMOT方法检测选用了anchor-free的CenterNet算法,克服了Anchor-based的检测框架中anchor和特征不对齐问题,深浅层特征融合使得检测和ReID任务各自获得所需要的特征,并且使用低维度ReID特征,提出了一种由两个同质分支组成的简单baseline来预测像素级目标得分和ReID特征,实现了两个任务之间的公平性,并获得了更高水平的实时多目标跟踪精度。
FairMOT属于JDE(Jointly learns the Detector and Embedding model )的一种。实验证明了现有的JDE方法存在一些不足,FairMOT根据这些不足进行了相关的改进。
综合速度和精度,本案例选用FairMot模型实现车辆跟踪计数。
3.2 模型训练
修改数据集配置信息,在configs/mot/vehicle/fairmot_dla34_30e_1088x608_bdd100k_vehicle.yml文件中:
_base_: [ '../fairmot/fairmot_dla34_30e_1088x608.yml' ] weights: output/fairmot_dla34_30e_1088x608_bdd100k_vehicle/model_final # for MOT training TrainDataset: !MOTDataSet dataset_dir: /home/aistudio/work image_lists: ['bdd100kmot_vehicle.train'] data_fields: ['image', 'gt_bbox', 'gt_class', 'gt_ide'] # for MOT evaluation # If you want to change the MOT evaluation dataset, please modify 'data_root' evalMOTDataset: !MOTImageFolder dataset_dir: /home/aistudio/work/bdd100kmot_vehicle data_root: images/val keep_ori_im: False # set True if save visualization images or video, or used in DeepSORT # for MOT video inference TestMOTDataset: !MOTImageFolder dataset_dir: dataset/mot keep_ori_im: True # set True if save visualization images or video ```%cd /home/aistudio/work !mkdir image_lists !cp bdd100kmot_vehicle/bdd100kmot_vehicle.train image_lists/%cd /home/aistudio/work/PaddleDetection-mot_feature_model !python -u tools/train.py -c configs/mot/vehicle/fairmot_dla34_30e_1088x608_bdd100k_vehicle.yml 断点接着训练添加:-r output/fairmot_dla34_30e_1088x608_bdd100k_vehicle/0
3.3 模型评估
本案例为大家提供了8GPUs,dla34,coco预训练,lr=0.0005 bs=16*8卡,12epoch(8epoch降lr)的模型。该模型额外添加了bdd100k数据中四轮车检测数据用于训练,对应的数据集请参考:https://aistudio.baidu.com/aistudio/datasetdetail/112117。
其他的一些配置如下:
norm_type: sync_bn use_ema: true ema_delay: 0.9998 TrainDataset: !MOTDataSet: dataset_dir: dataset/mot image_lists: ['bdd100kmot_vehicle.train','bdd100kdet_vehicle.train','bdd100kdet_vehicle.val'] data_fields: ['image','gt_box','gt_class','gt_ide'] ```%cd ~/work/PaddleDetection-mot_feature_model ! python3.7 tools/eval_mot.py -c configs/mot/vehicle/fairmot_dla34_30e_1088x608_bdd100k_vehicle.yml \ -o weights=/home/aistudio/work/fairmot_dla34_30e_1088x608_bdd100k_vehicle_sync_add_39.7.pdparams
3.4 模型优化
可变形卷积
可变形卷积网络(Deformable Convolution Network, DCN)顾名思义就是卷积的位置是可变形的,并非在传统的$$N × N$$的网格上做卷积,这样的好处就是更准确地提取到我们想要的特征(传统的卷积仅仅只能提取到矩形框的特征)。本实验在CenterNet head中加入了DCN,具体新的CenterNet head代码见centernet_head_dcn.py。在head中加入dcn后,模型的MOTA从原来的34.9%上升为39.3%,增长了4.4%。
数据增强
Mixup 是最先提出的图像混叠增广方案,其原理简单、方便实现,不仅在图像分类上,在目标检测上也取得了不错的效果。为了便于实现,通常只对一个 batch 内的数据进行混叠。
Mixup原理公式为:
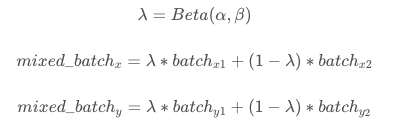
Mixup后图像可视化如下图所示:

在baseline中加入dcn后再加入mixup数据增强,模型MOTA为36.8%,比只加入dcn下降了2.5%。
具体为在fairmot_reader_1088x608.yml文件中TrainReader的sample_transforms下加入- Mixup: {alpha: 1.5, beta: 1.5},在TrainReader中加入mixup_epoch: 25。
mixup_epoch (int): 在前mixup_epoch轮使用mixup增强操作;当该参数为-1时,该策略不会生效。默认为-1。
指数移动平均(EMA)
在深度学习中,经常会使用EMA(指数移动平均)这个方法对模型的参数做平均,以求提高测试指标并增加模型鲁棒。指数移动平均(Exponential
Moving Average)也叫权重移动平均(Weighted Moving Average),是一种给予近期数据更高权重的平均方法。
本实验在baseline中加入dcn的基础上加入了EMA,ema_decay=0.9998。模型MOTA为38.5%,比只加入dcn下降了0.8%。
具体为在fairmot_dla34.yml文件中添加
use_ema: true ema_decay: 0.9998
conf和tracked阈值修改
在fairmot_dla34.yml文件中JDETracker下有conf_thres和tracked_thresh两个超参数,分别用于是检测的阈值和跟踪的阈值,默认均为0.4,将两者都改成0.2后,在baseline基础上加入dcn的模型,MOTA从39.3%降为35.7%,下降3.6%。
sync_bn
默认情况下,在使用多个GPU卡训练模型的时候,Batch Normzlization都是非同步的(unsynchronized),即归一化操作是基于每个GPU上的数据进行的,卡与卡之间不同步。在fairmot_dla34.yml文件中加入norm_type: sync_bn可实现多卡训练时归一化同步的功能。
baseline+dcn+ema基础上加上sync_bn MOTA从38.5%提升到了38.6%,提升了0.1%。
dla60
baseline中centernet的backbone为dla34,将dla34换成更大的dla60后,之前的预训练模型不能再用,在加入dcn的情况下,MOTA从39.3%降为22.5%,下降了16.8%。可见预训练模型的重要性。
dla60具体代码见dla.py文件,将class DLA(nn.Layer)中__init__函数输入参数depth改为60。
hardnet85
将baseline中centernet的backbone换为hardnet85,预训练模型在coco数据集上训练而得。hardnet85网络结构的配置文件见fairmot_hardnet85.yml。利用hardnet85训练的配置文件见fairmot_hardnet85_30e_1088x608.yml。在bdd100k数据集上训练模型的配置文件:fairmot_hardnet85_30e_1088x608_bdd100k_vehicle.yml。训练8个epoch的mota可达到39.1%。
在上面的实验基础上加入sync_bn,8卡训练epoch=12时,mota为39.8%。
继续在上面的基础上加入dcn,4卡训练epoch=12是MOTA为39.2%。
BDD100K数据集中所有四轮车
上面实验中训练集和验证集都只选用了BDD100K数据集中car,将BDD100K数据集中所有四轮车数据全都用于训练和验证后,coco预训练,lr=0.0005 bs=16*8卡,12epoch(8epoch降lr),mota为39.6%。
3.5 模型测试
测试图像,需要给定图片所在的文件夹。! unzip /home/aistudio/work/test_data/demo.zip -d
/home/aistudio/work/test_data/%cd
/home/aistudio/work/PaddleDetection-mot_feature_model/
! python3.7 tools/infer_mot.py -c configs/mot/vehicle/fairmot_dla34_30e_1088x608_bdd100k_vehicle.yml
-o weights=/home/aistudio/work/fairmot_dla34_30e_1088x608_bdd100k_vehicle_sync_add_39.7.pdparams
–image_dir=/home/aistudio/work/test_data/b251064f-8d92db81
–draw_threshold 0.2 --save_images测试视频:! python3.7 tools/infer_mot.py
-c configs/mot/vehicle/fairmot_dla34_30e_1088x608_bdd100k_vehicle.yml
-o weights=/home/aistudio/work/fairmot_dla34_30e_1088x608_bdd100k_vehicle_sync_add_39.7.pdparams
–video_file=/home/aistudio/work/test_data/demo2.mp4
–save_videos --draw_threshold 0.1> 如果出现视频帧为0的错误,尝试安装4.2.0.32版本的opencv-python。
3.6 模型导出
!python3.7 tools/export_model.py
-c configs/mot/vehicle/fairmot_dla34_30e_1088x608_bdd100k_vehicle.yml
-o weights=/home/aistudio/work/fairmot_dla34_30e_1088x608_bdd100k_vehicle_sync_add_39.7.pdparams


 微信联系
微信联系
