1. 项目说明
异常行为的识别与检测有着广泛的应用场景:
在公共区域,监控录像覆盖范围越来越广泛,以监控和防止各种异常行为的发生。
在生产线上,通过监控监测员工的生成动作是否规范。
在智能驾驶领域,通过监控监测司机是否有违规的行为,如打电话等。
在智慧课堂,通过教室内监控,查看是否有扰乱课堂秩序的事件发生。
在养老院、医院、独居老人生活的场所,通过视频监控,查看是否有摔倒等行为的发生。
…

异常行为检测有很多的难点,具体如下:

报名直播课,技术交流与合作可点击以下链接:
https://paddleqiyeban.wjx.cn/vj/YP1ixS1.aspx?udsid=970042
2. 安装说明
2.1 PaddleVideo安装
%cd /home/aistudio/work/PaddleVideo-develop/
!pip install -r requirements.txt
!pip install mpy
2.2 PaddleDetection安装
本案例给大家提供了PaddleDetection代码,解压:%cd /home/aistudio/work
!unzip -o PaddleDetection-release-2.0.zip
!mv PaddleDetection-release-2.0 PaddleDetectionPaddleDetection安装:# 安装其他依赖
%cd /home/aistudio/work/PaddleDetection/
!pip install -r requirements.txt
#编译安装paddledet
!python setup.py install下载训练好的检测模型参数:%cd /home/aistudio/work
!wget https://paddledet.bj.bcebos.com/models/faster_rcnn_r50_fpn_1x_coco.pdparams
3. 数据准备
视频来源于网络,侵删。本案例提供一个视频数据供参考:
/home/aistudio/work/data/abnormal_action_videos/abnormal_action.mp4
接下来提取视频帧用于目标检测(人检测),本案例以每秒2帧的帧率进行采样,具体命令参数如下:
第一个参数:视频所在目录;
第二个参数:抽取的视频帧存放目录;
第三个参数:帧率。%cd /home/aistudio/work/data
!bash extract_video_frames.sh abnormal_action_videos abnormal_action_frames 2利用PaddleDetection中FasterRCNN模型检测上步骤抽取得到的视频帧中的目标:
–infer_dir为上步骤视频帧保存目录;
–output_dir为检测结果保存目录;
PaddleDetection提供了对文件夹中所有图像进行检测的脚本,本案例需要对根目录下每个视频帧目录下图像进行检测,将多文件夹目标检测脚本infer_batch.py放到PaddleDetection的tools文件夹下;把多文件夹预测脚本trainer.py替换ppdet/engine/trainer.py:!cp /home/aistudio/work/infer_batch.py /home/aistudio/work/PaddleDetection/tools
!cp /home/aistudio/work/trainer.py
/home/aistudio/work/PaddleDetection/ppdet/engine/trainer.py%cd
/home/aistudio/work/PaddleDetection
!mkdir /home/aistudio/work/data/detection_result/
!python tools/infer_batch.py -c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml
-o weights=/home/aistudio/work/faster_rcnn_r50_fpn_1x_coco.pdparams
–infer_dir=/home/aistudio/work/data/abnormal_action_frames
–output_dir=/home/aistudio/work/data/detection_result/
–draw_threshold 0.5 --save_txt True通过PaddleDetection的FasterRCNN模型得到检测结果后,将检测结果转成SlowFast_FasterRCNN模型需要的输入格式:import os
import sys
import pickle
import glob
import cv2
#将目标检测结果整合成proposal文件
def generate_proposal_file(detection_result_dir,proposal_file_path):
“”"
self.proposals:
1j20qq1JyX4,0902
[[0.036 0.098 0.55 0.979 0.995518] # x1,y1,x2,y2,score
[0.443 0.04 0.99 0.989 0.977824]]
“”"
# 每个视频的文件夹名字列表
sub_dir_list = os.listdir(detection_result_dir)
proposals = {}
for sub_dir in sub_dir_list:
video_dir = os.path.join(detection_result_dir,sub_dir)
txt_files = glob.glob('{}/*.txt'.format(video_dir))
for txt_file in txt_files:
img_path = txt_file.replace(".txt",'.jpg')
img = cv2.imread(img_path)
sp = img.shape
height = sp[0]#height(rows) of image
width = sp[1]#width(colums) of image
file_name=txt_file.split("/")[-1].split("_")[-1].replace(".txt","")
key = sub_dir+","+file_name
#print(file_name,key)
person_list = []
#person 0.5414636731147766 738.5703735351562 756.7861328125 315.99468994140625 589.06494140625
with open(txt_file,'r') as f:
lines = f.readlines()
for line in lines:
items = line.split(" ")
object = items[0]
if object != "person":
continue
score = float(items[1])
#xmin, ymin, w, h = bbox
x1 = (float(items[2]))/width
y1 = ((float)(items[3]))/height
w = ((float)(items[4]))
h = ((float)(items[5]))
x2 = (float(items[2])+w)/width
y2 = (float(items[3])+h)/height
person_proposal = [x1,y1,x2,y2,score]
person_list.append(person_proposal)
proposals[key] = person_list
#for key,value in proposals.items():
# if '00001' in key:
# print(key,value)
with open(proposal_file_path, 'wb') as handle:
pickle.dump(proposals, handle, protocol=pickle.HIGHEST_PROTOCOL)if name == ‘main’:
detection_result_dir = “/home/aistudio/work/data/detection_result”
proposal_file_path = ‘/home/aistudio/work/data/frames_proposal_faster_rcnn.pkl’
generate_proposal_file(detection_result_dir,proposal_file_path) 接下来,以较大帧率(此处为30)抽取视频帧,用于模型输入:%cd /home/aistudio/work/data
!bash extract_video_frames.sh abnormal_action_videos abnormal_action_frames_30fps 30标签数据list文件为/home/aistudio/work/data/abnormal_action_list.pbtxt,注意标签id从1开始:
item {
name: "挥棍"
id: 1
}
item {
name: "打架"
id: 2
}
item {
name: "踢东西"
id: 3
}
item {
name: "追逐"
id: 4
}
item {
name: "争吵"
id: 5
}
item {
name: "快速奔跑"
id: 6
}
item {
name: "摔倒"
id: 7
}4. 模型选择
4.1 动作相关任务选型策略剖析
动作相关任务种类较多,下面就动作相关的任务进行描述总结,并给出适用场景和代表模型:

基于视频的异常行为检测是控制系统中关键技术之一。通过人监控多个视频不仅耗费人力,而且容易出现漏检情况。为了解决这个问题,可通过人工智能赋能安防,让安防领域视频监控更加智能高效。本案例基于SlowFast和Faster-RCNN两个模型,对视频中的异常进行进行检测。
动作可以被理解为是一个时空目标,相比于单纯依靠图像进行异常行为检测,基于时空多维信息能够提高检测的准确率,减少误检情况的发生。
4.2 SlowFast
SlowFast 由 Facebook FAIR 的何恺明团队提出,用于视频识别。SlowFast 包含两条路径:
Slow pathway
Fast pathway
Slow pathway 运行低帧率,用于捕捉空间语义信息;Fast pathway 运行高帧率,获取精确的时间运动信息。通过降低通道数量,Fast pathway 分支可以变成轻量的网络,同时也能够学到视频中有用的时域信息。
动机
SlowFast 受到灵长类视觉系统中视网膜神经节细胞的生物学研究的启发。研究发现,这些细胞中约80%的都是P-cell,约15~20% 是 M-cell。M-cell 以较高的时间频率工作,能够对快速的时间变化作出响应,但是对空间细节和颜色不敏感。P-cell 则提供良好的空间细节和颜色信息,但时间分辨率较低,对刺激反应比较慢。
SlowFast 与此相似:
SlowFast 有两条路径,分别处理低帧率和高帧率;
Fast pathway 用于捕捉快速变化的动作,但涉及到的细节信息较少,与M-cell类似;
Fast pathway 是轻量的,与M-cell的占比类似。
视觉内容的类别空间语义变化通常比较缓慢。比如,挥手不会在这个动作进行期间改变“手”的类别;一个人从走路变为跑步,识别结果也一直是“人”。因此类别语义的识别(以及颜色、纹理、光照等)可以以较慢的速度刷新。另一方面,正在执行的动作比其主体识别变化的速度要快得多,如拍手、挥手、摇摆、走路或跳跃。因此需要用较快的帧率刷新(高时间分辨率),来对快速变化的动作进行建模。
思路
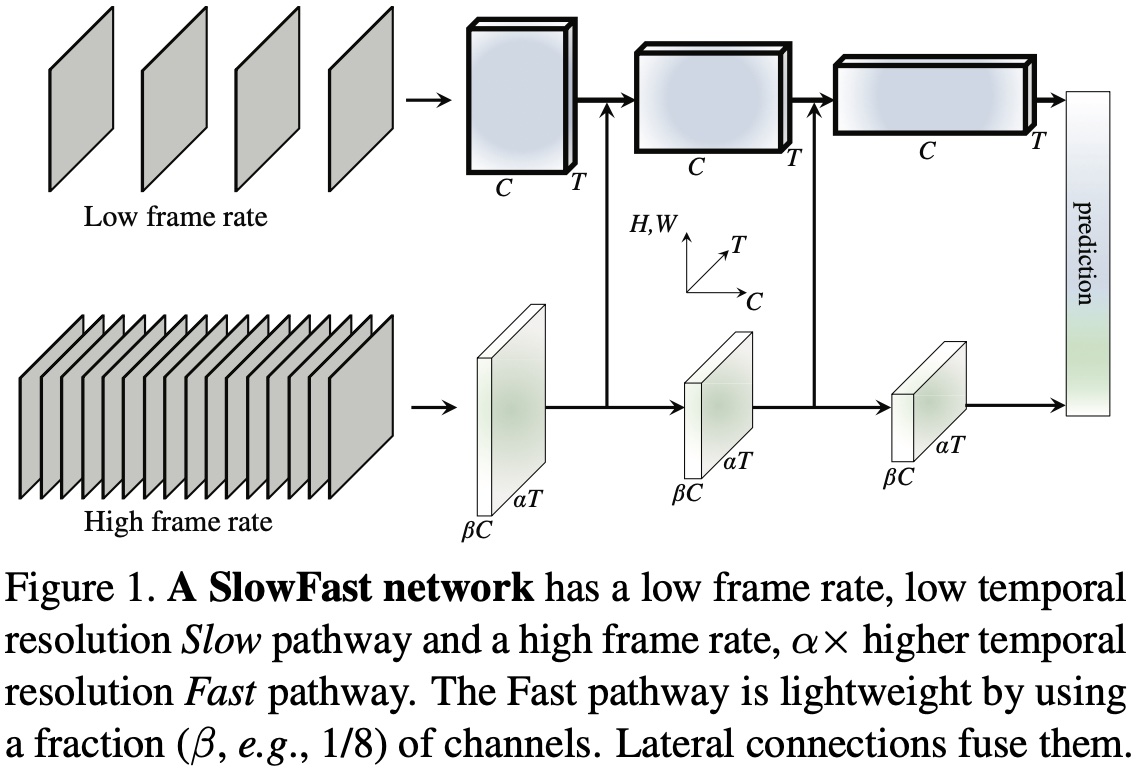
SlowFast网络结构
如上图所示,一条路径用于捕获图像或稀疏帧提供的语义信息,以低帧率运行,刷新速度慢。另一条路径用于捕获快速变化的动作,刷新速度快、时间分辨率高,该路径是轻量级的,仅占整体计算量的20%。这是由于这条路径通道较少,处理空间信息的能力较差,但空间信息可以由第一个路径以简洁的方式来处理。
依据两条路径运行的帧率高低不同,作者将第一条路径称为“Slow pathway”;第二条路径称为“Fast pathway”;两条路径通过横向连接进行融合。
Slow Pathway
Slow pathway 可以是任意在视频片段上做时空卷积的模型,如时空残差网络,C3D,I3D,Non-local网络等。Slow pathway 的关键之处在于对视频帧进行采样时,时间步长ττ较大,也就是说,只处理ττ帧中的一帧。这里,作者建议 ττ的取值为 16,对于 30fps 的视频,差不多每秒采样 2 帧。如果 Slow pathway 采样的帧数是 T,那么原始视频片段的长度为 T×τT×τ。
Fast Pathway
高帧率
Fast pathway 的目的为了在时间维度上有良好的特征表示,Fast pathway 的时间步长 ταατ 较小,其中 α>1α>1 是 Slow pathway 和 Fast pathway 之间帧率比,作者建议 αα 的取值为 8。由于两条路径在同一个视频上进行操作,因此 Fast pathway 采样到的帧数量为 αTαT ,比 Slow pathway 密集 αα 倍。
高时间分辨率特征
Fast pathway 具有高输入分辨率,同时整个网络结构会运行高分辨率特征。在最后的分类全局池化层之前作者没有采用时间下采样层,因此特征张量在时间维度上一直保持在 αTαT。
低通道容量
Fast pathway 是一个与 Slow pathway 相似的卷积网络,但通道数只有 Slow pathway 的 ββ 倍,其中 β<1β<1 ,作者建议 ββ 的取值为 1881 。这使得 Fast pathway 比 Slow pathway 的计算更高效。
低通道容量可以理解为表示空间语义信息的能力较弱。由于 Fast pathway 的通道数更少,因此 Fast pathway 的空间建模能力应该弱于 Slow pathway。但 SlowFast 的实验结果表明这反而是有利的,它弱化了空间建模能力,却增强了时间建模能力。
横向连接
作者通过横向连接对两条路径的信息进行融合,使得 Slow pathway 知道 Fast pathway 在学习什么。作者在两条路径中的每个“阶段”上使用一个横向连接,由于两条路径的时间维度不同,因此在进行横向连接时需要通过变换对两条路径的维度进行匹配。最后,将两条路径的输出进行全局平均池化,并将池化后的特征拼接在一起作为全连接分类器层的输入。
实例化
SlowFast 模型的思想是通用的,可以用不同的主干网络来实现。如下图所示是一个 SlowFast 实例化的例子,其中黄色是通道数量,绿色是时序帧分辨率。
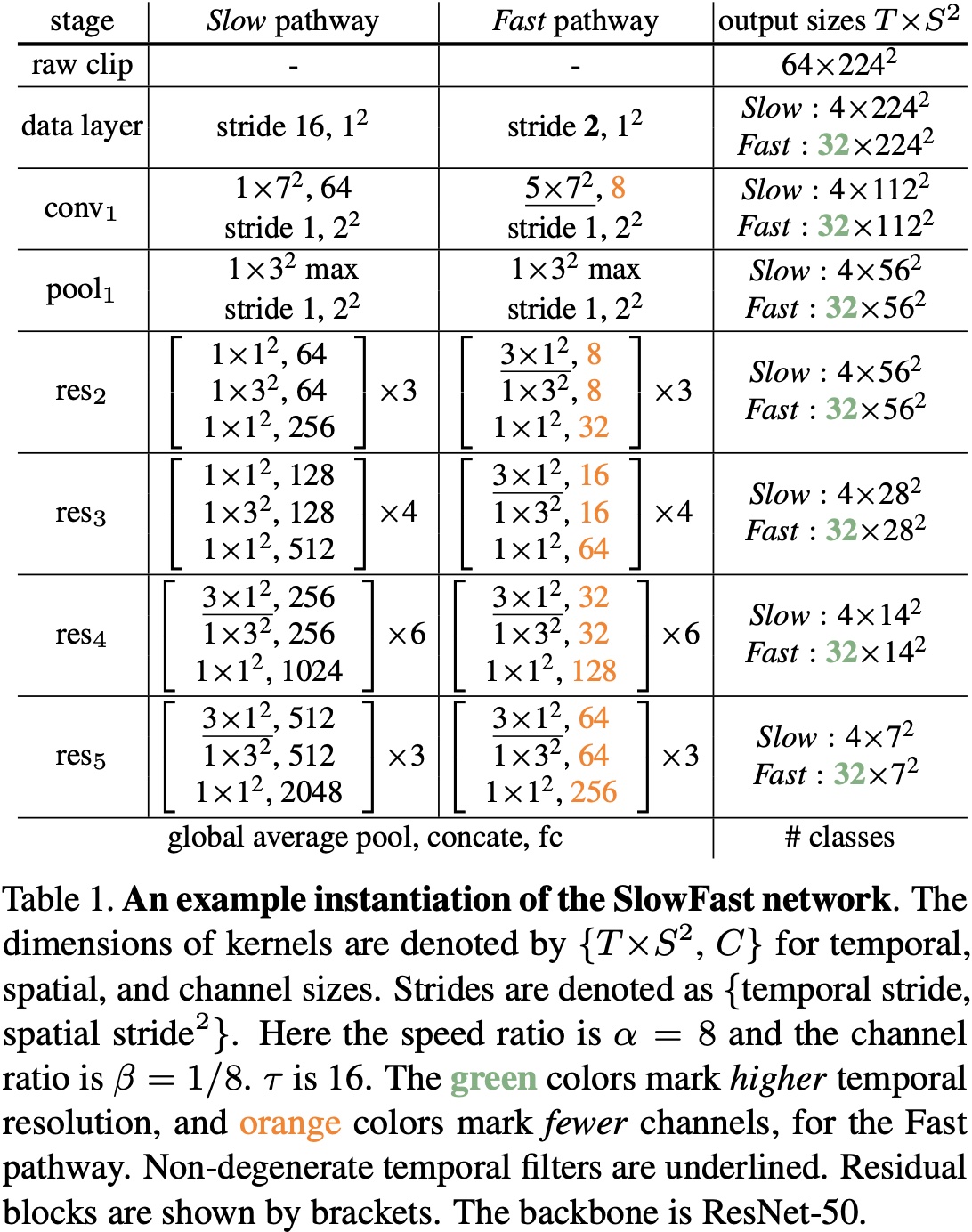
实例化
作者用 T×S2T×S2 表示时空尺度,其中 T 是时间长度,S 是正方形裁剪区域的宽和高。
Slow Pathway
Slow pathway 是一个具有时间步长的 3D ResNet,网络时间维度的输入帧数 T = 4,从 64 帧视频片段中稀疏采样得到,时间步长 τ=16τ=16。作者没有采用时间下采样在实例化中,由于当输入步长较大时,这样做是有害的。
Slow pathway 与 C3D/I3D 模型不同,从 conv_1 到 res_3 的滤波器本质上都是2D卷积核,只有 res_4 和 res_5 使用的是非退化时间卷积。之所以采用这种设计是由于作者通过实验发现,在早期层使用时间卷积会降低准确率。作者认为是由于当物体快速移动且时间步长较大时,在一个时间感受野内的相关性就很小,除非空间感受野也足够地大。
Fast Pathway
Fast pathway 的时间分辨率较高,通道容量较低。Fast pathway 的每个模块中都使用了非退化时间的卷积,并且没有使用时间下采样层。之所以这样设计是因为作者发现 Fast pathway 的时间卷积有很好的时间分辨率,可以捕捉细节动作。
横向连接
横向连接是从 Fast pathway 到 Slow pathway,在融合之前需要保证两个维度是匹配的,Slow pathway 的特征维度是 {T,S2,C}{T,S2,C} ,Fast pathway 的特征维度是 {αT,S2,βC}{αT,S2,βC} ,在连接方案上作者进行了如下实验:
Time-to-channel:对 αT,S2,βCαT,S2,βC 进行变形和转置,得到 {T,S2,αβC}{T,S2,αβC} ,也就是说将所有的 αα 帧放入一帧的多个通道内。
Time-strided sampling:每 αα 帧,采样一帧,所以 αT,S2,βCαT,S2,βC 就变成了 {T,S2,βC}{T,S2,βC} 。
Time-strided convolution:使用 3D 卷积,卷积核大小是 5×125×12 ,输出通道数为 2βC2βC ,步长为 αα 。
5. 模型训练
-c后面的参数是配置文件的路径。-w后面的参数是finetuning或者测试时的权重。--validate参数表示在训练过程中进行模型评估。
本案例基于在AVA数据集上训练好的模型进行迁移学习:解压预训练模型:!unzip -o
/home/aistudio/work/AVA_SlowFast_FastRcnn_best.pdparams.zip -d
/home/aistudio/work/# 模型训练
%cd /home/aistudio/work/PaddleVideo-develop/
!python main.py --validate -w /home/aistudio/work/AVA_SlowFast_FastRcnn_best.pdparams
-c /home/aistudio/work/abnoraml_action.yaml
6. 模型评估
解压本案例提供的训练好的模型:
!unzip
/home/aistudio/work/abnormal_action_SlowFast_FastRcnn_index_from_1.pdparams.zip
-d /home/aistudio/work/%cd /home/aistudio/work/PaddleVideo-develop/
!python main.py --test
-w /home/aistudio/work/abnormal_action_SlowFast_FastRcnn_index_from_1.pdparams
-c /home/aistudio/work/abnoraml_action.yaml
7. 模型预测
模型应用具体流程框图如下:
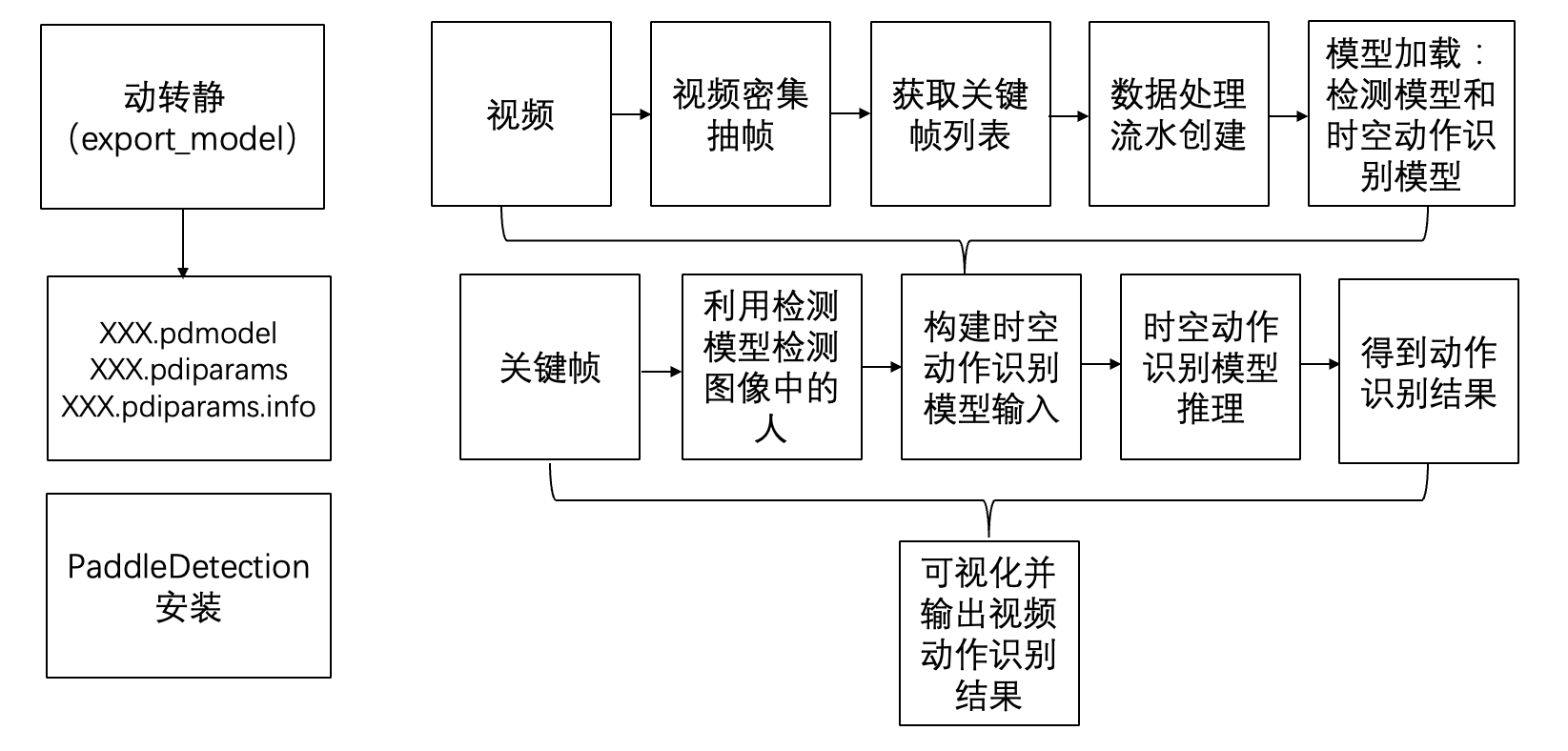
基于动态图模型推理:%cd /home/aistudio/work/PaddleVideo-develop/
!python tools/ava_predict.py
-c /home/aistudio/work/abnoraml_action.yaml
-w /home/aistudio/work/abnormal_action_SlowFast_FastRcnn_index_from_1.pdparams
–video_path /home/aistudio/work/data/wave_9.mp4
–detection_model_name ‘faster_rcnn/faster_rcnn_r50_fpn_1x_coco’
–detection_model_weights ‘/home/aistudio/work/faster_rcnn_r50_fpn_1x_coco.pdparams’
8. 模型部署
在实际应用中,应该用静态图模型。
导出静态图模型:%cd /home/aistudio/work/PaddleVideo-develop/
!python tools/export_model.py
-c /home/aistudio/work/abnoraml_action.yaml
-o inference_output
-p
/home/aistudio/work/abnormal_action_SlowFast_FastRcnn_index_from_1.pdparamsPaddle
Inference 是飞桨的原生推理库, 作用于服务器端和云端,提供高性能的推理能力。Paddle Inference
功能特性丰富,性能优异,针对不同平台不同的应用场景进行了深度的适配优化,做到高吞吐、低时延,保证了飞桨模型在服务器端即训即用,快速部署。
本案例基于Paddle Inference中python部署完成预测:
(1) 引用 paddle inference 预测库
import paddle.inference as paddle_infer
(2) 创建配置对象,并根据需求配置
# 创建 config,并设置预测模型路径
config = paddle_infer.Config(args.model_file, args.params_file)
(3) 根据Config创建预测对象
predictor = paddle_infer.create_predictor(config)
(4) 设置模型输入 Tensor
# 获取输入的名称
input_names = predictor.get_input_names()
input_handle = predictor.get_input_handle(input_names[0])
# 设置输入
fake_input = np.random.randn(args.batch_size, 3, 318, 318).astype("float32")
input_handle.reshape([args.batch_size, 3, 318, 318])
input_handle.copy_from_cpu(fake_input)
(5) 执行预测
predictor.run()
(6) 获得预测结果
output_names = predictor.get_output_names()
output_handle = predictor.get_output_handle(output_names[0])
output_data = output_handle.copy_to_cpu() # numpy.ndarray类型基于导出的模型做推理:%cd /home/aistudio/work/PaddleVideo-develop/
!python tools/predict.py
-c /home/aistudio/work/abnoraml_action.yaml
–input_file “/home/aistudio/work/data/wave_9.mp4”
–model_file “/home/aistudio/work/PaddleVideo-develop/inference_output/AVA_SlowFast_FastRcnn.pdmodel”
–params_file “/home/aistudio/work/PaddleVideo-develop/inference_output/AVA_SlowFast_FastRcnn.pdiparams”
–use_gpu=True
–use_tensorrt=False
9. 模型优化
本案例具体优化实验汇总如下:

学习率
本案例用到的损失函数为CustomWarmupPiecewiseDecay,Warmup是学习率预热方法,在训练开始时选择较小的学习率训练,再修改为预先设置的学习率进行训练。通过调小开始的学习率和基础学习率,模型精度得到提升。

alpha超参
alpha参数是SlowFast模型的超参数,控制Slow分支和Fast分支帧的刷新频率,通过调小alpha参数,配合学习率参数修改,模型精度有了进一步提升。
具体修改配置如下:
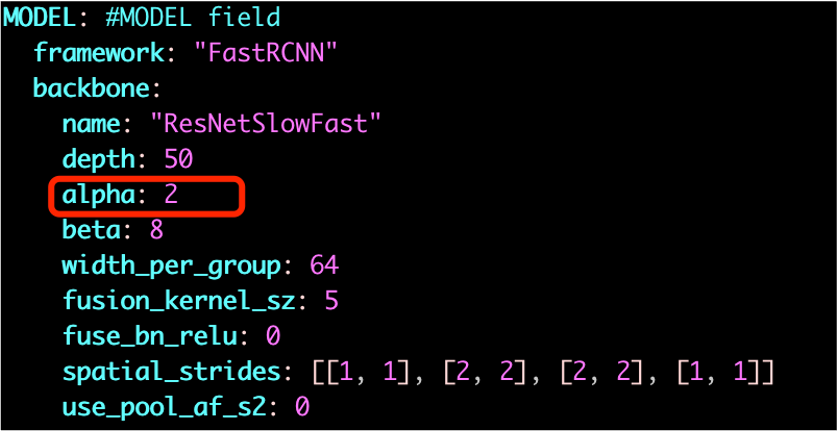
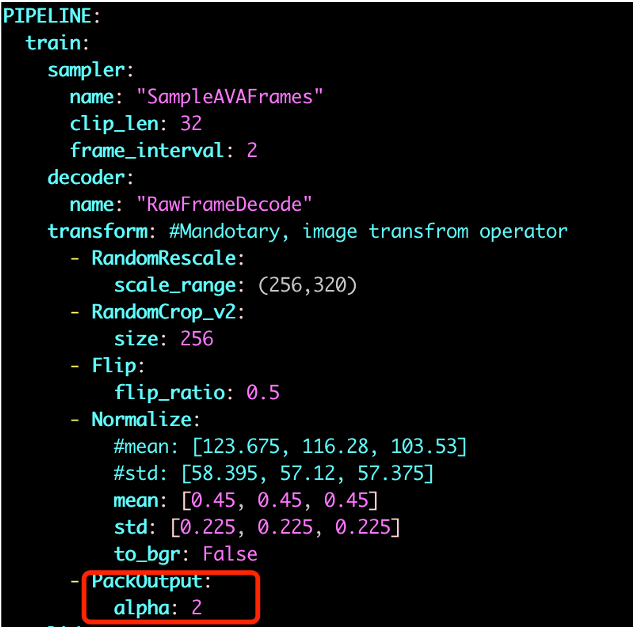
warmup_start_lr: 0.002,step_base_lr: 0.04
AVA数据集中异常行为测试优化
| AVA数据集动作 | 训练样本 | 测试样本 | 优化前AP | 优化后AP |
|---|---|---|---|---|
| 摔倒 | 290 | 88 | 0.3413 | 0.3466 |
| 吸烟 | 2855 | 673 | 0.4884 | 0.5297 |
| 打架 | 2602 | 467 | 0.5480 | 0.5616 |
| 踢某人 | 49 | 11 | 0.0070 | 0.0064 |
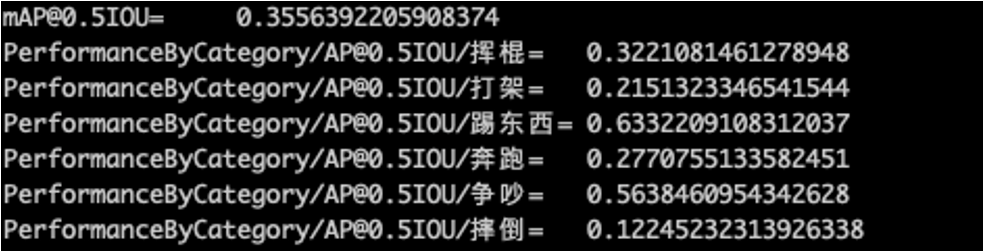
由于“踢某人”动作数据量太少,暂不考虑。从表中可以看出,本案例优化对于AVA数据集中的3个异常动作起作用。
数据质量对模型精度影响
| 摔倒 | 样本数量 | AP |
|---|---|---|
| AVA | 378 | 0.3466 |
| 自建 | 1754 | 0.1225 |
同样是摔倒动作,自建数据质量不高,虽然数量比AVA多,但是AP值不高,可见数据质量对模型精度影响较大。
注:此处不考虑验证集不同对最终结果的影响。
资源
更多资源请参考:
更多深度学习知识、产业案例,请参考:awesome-DeepLearning
更多视频相关模型,请参考:PaddleVideo
更多学习资料请参阅:飞桨深度学习平台


 微信联系
微信联系
