1 项目说明
1.1 项目背景
花样滑冰起源最早可追溯到12世纪的北欧,1892年国际滑冰联盟在荷兰正式成立,并制定了该项目的比赛规则1924年的第1届冬季奥运会就将花样滑冰列为比赛项目。但是在我国,该项运动在国内的普及度却并不高。中国最高级的组织机构:中国花样滑冰协会成立于2018年1月18日的北京。因此,很多观众在观看花样滑冰表演或比赛时,除了直观感受运动员展示出来的花样滑冰的艺术美感之外,可能很少有一些对花样滑冰专业技术动作,例如点冰跳、刀刃跳、空中旋转
周数与组合跳跃等有所认识。
本项目首次将基于人体骨架关键点的人类动作识别算法 ST-GCN,即时空图卷积网络模型,运用于花样滑冰动作识别,可以实时地识别视频中花样滑冰运动员的技术动作并添加标注予以显示,帮助更多入门级别的观众了解花样滑冰,使其能更好的比较和体会不同的花样滑冰动作,对花样滑冰运动的进一步推广有积极的作用。

 </figure>
</figure>欢迎报名直播课加入交流群,如需更多技术交流与合作可点击以下链接
https://paddleqiyeban.wjx.cn/vj/Qlb0uS3.aspx?udsid=531417
1.2 项目亮点
花样滑冰细粒度分类数据集。 竞技体育是动作分析的难点。数据集Figure Skating Dataset 旨在通过花样滑冰研究人体的运动。在花样滑冰运动中,人体姿态和运动轨迹相较于其他运动呈现复杂性强、类别多的特点,对于研究视频中的人体动态是非常好的素材。希望对我国竞技体育辅助训练和评估做出重要贡献。
简单轻量模型。 ST-GCN模型非常简洁,容易理解。作为骨骼点动作识别开山之作,以简单的网络结构就可以完成复杂任务,并且达到不错的效果。具体实现过程中,整个模型核心部分仅仅涉及到三个卷积核。正因如此,训练效率也大大提升。
2 项目难点
时空序列视频内容分类的模型较少
以帧为最小单位的光流法分类参数多,难以训练
花样滑冰动作细粒度分类的类间方差很大,类内方差很小:
花样滑冰动作有跳跃、旋转、托举、步伐及转体、燕式步,而跳跃当中又有更加精细的动作。
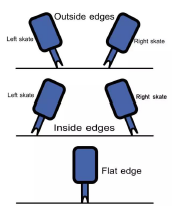
以跳跃为例:跳跃式花样滑冰中最重要的动作要素之一。跳跃按照选手起跳与落冰所用兵刃方式与空中旋转周数分为多种,因此可以产生多种组合,这就增加了分类的难度。如下图为滑冰鞋冰刃示意图:
如下图,左图为Salchow跳,右图为Loop跳。可见两种跳跃非常相似,区别仅在于脚步动作。
<figure> </figure>

3 解决方案
在动作识别领域中,不仅仅需要学习到画面中人物动作的空间特征,同时也需要学习到时间维度的特征。在传统动作识别中有一个经典方法TSN (Temporal Segment Networks for Action Recognition in Video)
但是TSN有如下缺点:
时间信息不重要,往往通过一帧就可以判别动作类型
不以人体为中心,模型做出的判断通过对整体画面来识别
图片数据量大,难以拟合
因此,本案例通过选择ST-GCN来完成对花样滑冰中动作姿态的识别任务
该模型由香港中文大学-商汤科技联合实验室在AAAI 2018 录用论文「Spatial Temporal Graph Convolutional Networks for Skeleton based Action Recognition」中提出,不仅为解决基于人体骨架关键点的人类动作识别问题提供了新颖的思路,在标准的动作识别数据集上也取得了较大的性能提升。
 </figure>
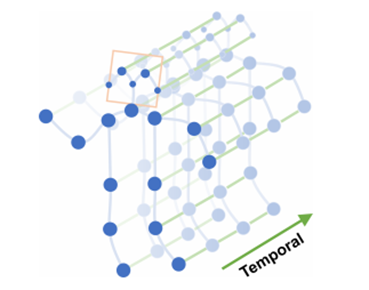
</figure>时空图卷积网络模型ST-GCN通过将图卷积网络(GCN)和时间卷积网络(TCN)结合起来,扩展到时空图模型,设计出了用于行为识别的骨骼点序列通用表示,该模型将人体骨骼表示为图的数据结构,如下图所示,其中图的每个节点对应于人体的一个关节点。图中存在两种类型的边,即符合关节的自然连接的空间边(spatial edge)和在连续的时间步骤中连接相同关节的时间边(temporal edge)。在此基础上构建多层的时空图卷积,它允许信息沿着空间和时间两个维度进行整合。
 </figure>
</figure>要完成通过ST-GCN识别动作类别,首先要将原始视频数据通过openpose转化为骨骼点数据。完整流程为下图所示步骤。
<figure> </figure>
4 数据准备
4.1 FSD数据集介绍
本案例使用数据集为Figure Skating30数据集(FSD-30)是在Figure Skating10数据集(FSD-10).基础上增加了细粒度分类。为简单起见,以FSD-10做介绍。
在FSD中,所有的视频素材从2017 到2018 年的花样滑冰锦标赛中采集。源视频素材中视频的帧率被统一标准化至每秒30 帧,并且图像大小是1080 * 720 来保证数据集的相对一致性。之后我们通过2D姿态估计算法Open Pose对视频进行逐帧骨骼点提取,最后以.npy格式保存数据集。更多信息可参考:FSD-10
 </figure>
</figure>如下图所示为FSD-10所包含的动作分类:
 </figure>
</figure>案例提供FSD-30训练数据集与测试数据集的目录结构如下所示:
train_data.npy # 2922 train_label.npy # 2922 test_A_data.npy # 628 test_B_data.npy # 634
test_A测试集暂未公布
其中train_label.npy通过np.load()读取后会得到一个一维张量,每一个元素为一个值在0-29之间的整形变量代表动作的标签;data.npy文件通过np.load()读取后,会得到一个形状为N×C×T×V×M的五维张量,每个维度的具体含义如下:
| 维度符号 | 维度值大小 | 维度含义 | 补充说明 |
|---|---|---|---|
| N | 样本数 | 代表N个样本 | 无 |
| C | 3 | 分别代表每个关节点的x, y坐标和置信度 | 每个x,y均被放缩至-1到1之间 |
| T | 1500 | 代表动作的持续时间长度,共有1500帧 | 有的动作的实际长度可能不足1500,例如可能只有500的有效帧数,我们在其后重复补充0直到1500帧,来保证T维度的统一性 |
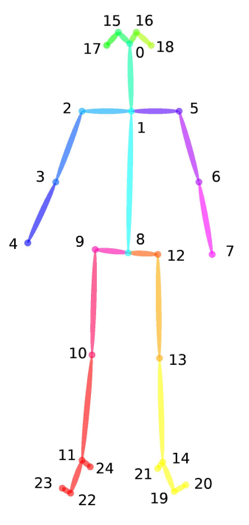
| V | 25 | 代表25个关节点 | 具体关节点的含义可看下方的骨架示例图 |
| M | 1 | 代表1个运动员个数 | 无 |
骨架示例图:
 </figure>
</figure>4.2 花样滑冰视频转化为骨骼点数据
这一部分为FSD作者团队提供了将原始视频数据转化为FSD数据格式的方法,由于用到了openpose等,不便于在AI studio中运行,用户可自行在本地配置相应环境后运行。在这里只进行简单介绍。
花样滑冰数据提取采用了openpose,通过其提供的demo或是相应的api来实现数据的提取,因此需要用户配置openpose环境。
如下是通过花样滑冰数据集构建项目Skeleton scripts提取骨骼点数据方法的具体介绍。
step1 安装openpose
参考:https://github.com/CMU-Perceptual-Computing-Lab/openpose
step2 测试openpose提供demo
这里通过测试openpose的demo程序来验证是否安装成功。
demo1:检测视频中身体骨骼点(以linux系统为例):
./build/examples/openpose/openpose.bin --video examples_video.avi --write_json output/ --display 0 --render_pose 0
执行成功之后会在output/路径下生成视频每一帧骨骼点数据的json文件。
demo2:检测视频中身体+面部+手部骨骼点(以linux系统为例):
./build/examples/openpose/openpose.bin --video examples_video.avi --write_json output/ --display 0 --render_pose 0 --face --hand
执行成功之后会在output/路径下生成视频每一帧身体+面部+手部骨骼点数据的json文件。
step3 视频及相关信息处理
由于Skeleton scripts为制作花样滑冰数据集所用,因此此处步骤可能存在不同程度误差,实际请用户自行调试代码。
将要转化的花样滑冰视频储存到Skeleton scripts的指定路径(可自行创建):
./skating2.0/skating63/
同时需要用户自行完成对视频信息的提取,保存为label_skating63.csv文件,储存到如下路径中(可自行创建):
./skating2.0/skating63/ ./skating2.0/skating63_openpose_result/
label_skating63.csv中格式如下:
| 动作分类 | 视频文件名 | 视频帧数 | 动作标签 |
|---|
此处用户只需要输入视频文件名(无需后缀,默认后缀名为.mp4,其他格式需自行更改代码),其他三项定义为空字符串即可,不同表项之间通过 ‘,’ 分割。
step4 执行skating_convert.py:
注意,这一步需要根据用户对openpose的配置进行代码的更改,主要修改项为openpose路径、openpose-demo路径等,具体详见代码。
本脚步原理是调用openpose提供的demo提取视频中的骨骼点,并进行数据格式清洗,最后将每个视频的提取结果结果打包成json文件,json文件储存在如下路径:
./skating2.0/skating63_openpose_result/label_skating63_data/
step5 执行skating_gendata.py:
将json文件整理为npy文件并保存,多个视频文件将保存为一个npy文件,保存路径为:
./skating2.0/skating63_openpose_result/skeleton_file/
通过上述步骤就可以将视频数据转化为无标签的骨骼点数据。
最后用户只需将npy数据输入送入网络开始模型测试,亦可通过预测引擎推理(如下)。
4.3 数据集导入项目
数据集可以从此链接处下载。数据集下载完成后,可以将数据集上传到aistudio项目中,上传后的数据集路径在/home/aistudio/data目录下。
如果是直接fork的本项目,在/home/aistudio/data 目录下已经包含了下载好的训练数据和测试数据。#解压数据集
!unzip -o /home/aistudio/data/data126425/FSD30.zip -d /home/aistudio/work/dataset/# 检查数据集所在路径
!tree -L 3 /home/aistudio/work/dataset
5 模型选择
PaddleVideo对于骨骼点动作识别算法主要提供了两种模型,ST-GCN和AGCN。
ST-GCN(Spatial Temporal Graph Convolutional Networks for Skeleton-based Action Recognition):第一次提出将GCN运用于骨骼行为识别之中。它可以从数据中自动地学习空间(GCN)和时间(TCN)的patterns,这使得模型具有很强的表达能力和泛化能力。
AGCN为对ST-GCN模型进行了优化,实现了精度更高的AGCN模型,模型优化细节参考AGCN模型解析.优化方向主要参考了ST-GCN,2s-AGCN(Two-Stream Adaptive Graph Convolutional Networks for Skeleton-based Action Recognition),MS-AGCN(Skeleton-based Action Recognition with Multi-Stream Adaptive Graph Convolutional Networks)
除此之外,还有在2019年发表在CVPR上的AS-GCN和2s-AGCN,都是以ST-GCN为基础上进行改进优化。进一步有MS-G3D(Disentangling and Unifying Graph Convolutions
for Skeleton-based Action Recognition),其提出了多尺度图卷积和统一的时空卷积,建立了可以学习复杂时空关系的统一时空模型。
在本案例中以最基础的ST-GCN介绍。
6 ST-GCN详细代码介绍
ST-GCN的网络结构大致可以分为三个部分,首先,对网络输入一个五维矩阵(N,C,T,V;M)(N,C,T,V;M).其中N为视频数据量;C为关节特征向量,包括(x,y,acc)(x,y,acc);T为视频中抽取的关键帧的数量;V表示关节的数量,在本项目中采用25个关节数量;M则是一个视频中的人数,然后再对输入数据进行Batch Normalization批量归一化,接着,通过设计ST-GCN单元,引入ATT注意力模型并交替使用GCN图卷积网络和TCN时间卷积网络,对时间和空间维度进行变换,在这一过程中对关节的特征维度进行升维,对关键帧维度进行降维,最后,通过调用平均池化层、全连接层,并后接SoftMax层输出,对特征进行分类
6.1 GCN部分
图卷积网络(Graph Convolutional Network,GCN)借助图谱的理论来实现空间拓扑图上的卷积,提取出图的空间特征,具体来说,就是将人体骨骼点及其连接看作图,再使用图的邻接矩阵、度矩阵和拉普拉斯矩阵的特征值和特征向量来研究该图的性质。
在原论文中,作者提到他们使用了「Kipf, T. N., and Welling, M. 2017. Semi-supervised classification with graph convolutional networks. In ICLR 2017」中的GCN架构,其图卷积数学公式如下:
fout=Λ− 12(A+I)Λ− 12finWfout=Λ− 21(A+I)Λ− 21finW
其中,foutfout为输出,A为邻接矩阵,I为单位矩阵,Aii= ∑j(Aij+Iij)Aii= ∑j(Aij+Iij), W是需要学习的空间矩阵。
但是在实际的应用中,最简单的图卷积已经能达到很好的效果,所以在实际应用中,作者采用的是D−1AD−1A图卷积核。D为度矩阵。
本项目中GCN部分优化:
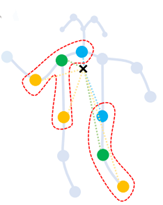
在原ST-GCN实现中,作者对于图卷积实现过程中,对称归一化形式的Laplace矩阵(Λ− 12(A+I)Λ− 12)(Λ− 21(A+I)Λ− 21)使用了注意力机制,使其部分可学习。原ST-GCN将骨骼点构成的图,根据不同的动作划分为了三个子图(A1,A2,A3)(A1,A2,A3)(如下图),分别表达向心运动、离心运动和静止的动作特征。
由此产生了三个卷积核A1^,A2^,A3^A1
,A2,A3
,对于多核的图卷积表达式:
∑k∑v(XWk)nkctvAkvw^=Xnctw^∑k∑v(XWk)nkctvAkvw
=Xnctw
 </figure>
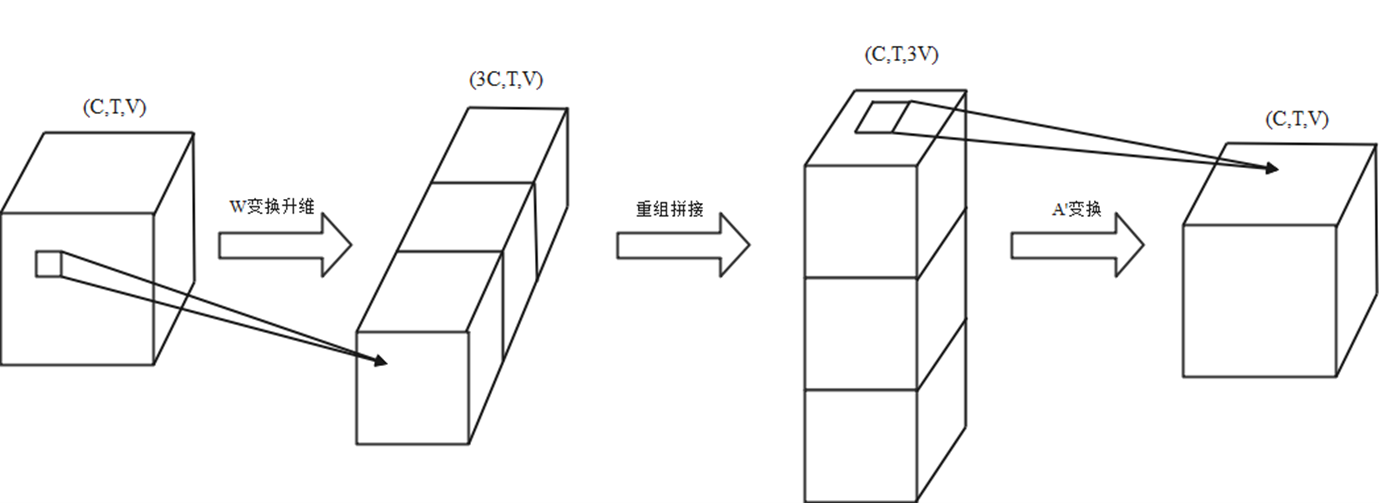
</figure>通过大量实验发现,将其随机设为完全可学习的矩阵(A′)(A′),使其随着训练,自动学习到骨骼点之间的连接关系,获得了更好的效果。
同时,这一步的搭建需要使用爱因斯坦求和约定:nkctv,kvw→nctw.
本项目中采用随机划分的方式,使得子图的划分可以被学习,并且对三个子图的图卷积合并为一个,进行并行计算,提升了算法性能,同时避免使用了paddle中没有提供的爱因斯坦求和约定,实现了GCN的构建,并且对其优化。
通过这两步优化,最终实现的图卷积形式为A′finWA′finW,如下图所示,其中W作为对输入的升维变换,同时将输入划分为三部分;然后通过对矩阵重组拼接,对三个部分(三个子图)进行A′A′的特征变换。
 </figure>
</figure>#准备环境
import paddle
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pickle
#全局变量
BATCH_SIZE=32class GCN(paddle.nn.Layer):
def init(self,in_channels,out_channels,stride=1):
super(GCN, self).init()
self.conv1=paddle.nn.Conv2D(in_channels=in_channels,out_channels=3out_channels,kernel_size=1,stride=1)
self.conv2=paddle.nn.Conv2D(in_channels=253,out_channels=25,kernel_size=1)
def forward(self, x): # X----[N,C,T,V] x=self.conv1(x) N,C,T,V=paddle.shape(x) x=paddle.reshape(x,[N,C//3,3,T,V]) x=paddle.transpose(x,perm=[0,1,2,4,3]) x=paddle.reshape(x,[N,C//3,3*V,T]) x=paddle.transpose(x,perm=[0,2,1,3]) x=self.conv2(x) x=paddle.transpose(x,perm=[0,2,1,3]) x=paddle.transpose(x,perm=[0,1,3,2]) return x### 6.2 TCN部分
ST-GCN单元通过GCN学习空间中相邻关节的局部特征,而时序卷积网络(Temporal convolutional
network,TCN)则用于学习时间中关节变化的局部特征。如图表4,TCN相较于CNN,对时间序列提取特征时,不再受限于卷积核的大小。对普通卷积,需要更多层才能采集到一段时间序列的特征,而TCN中采用的膨胀卷积(Dilated
Convolution),通过更宽的卷积核,可以采样更宽的信息。卷积核先完成一个节点在其所有帧上的卷积,再移动到下一个节点,如此便得到了骨骼点图在叠加下的时序特征。对于TCN网络,我们通过使用9×19×1的卷积核进行卷积。
为了保持总体的特征量不变,当关节点特征向量维度©成倍变化时,我们的步长采取2,其余采取1。
下图为TCN膨胀卷积示意图。
 </figure>
</figure>class TCN(paddle.nn.Layer):
def init(self,in_channels,out_channels,stride=1):
super(TCN, self).init()
self.conv=paddle.nn.Conv2D(in_channels=in_channels,out_channels=out_channels,kernel_size=(9,1),padding=(4,0),stride=(stride,1))#补零,4
#C=64
def forward(self, x):
x=self.conv(x)
return x### 6.3 ST-GCN单元
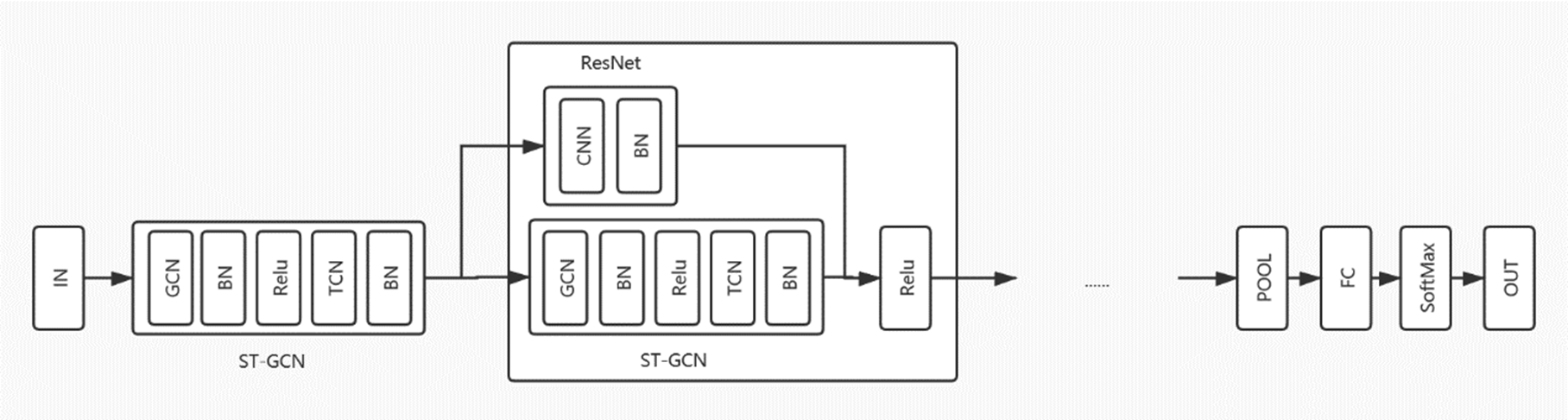
本项目根据ST-GCN网络的构建在参考已发布的论文基础上又有所改进和创新。
图为本项目中构建的ST-GCN网络结构图。
 </figure>
</figure>class LoopNet(paddle.nn.Layer):
def init(self,in_channels,out_channels,stride=1,if_res=1):
super(LoopNet, self).init()
self.bn_res=paddle.nn.BatchNorm2D(out_channels)
self.conv_res=paddle.nn.Conv2D(in_channels=in_channels,out_channels=out_channels,kernel_size=1,stride=(stride,1))
self.gcn=GCN(in_channels=in_channels,out_channels=out_channels)
self.bn1=paddle.nn.BatchNorm2D(out_channels)
self.tcn=TCN(in_channels=out_channels,out_channels=out_channels,stride=stride)
self.bn2=paddle.nn.BatchNorm2D(out_channels)
self.if_res=if_res
self.out_channels=out_channels
def forward(self, x):
if(self.if_res):#残差层
y=self.conv_res(x)
y=self.bn_res(y)
x=self.gcn(x) #gcn层
x=self.bn1(x) #bn层
x=paddle.nn.functional.relu(x)
x=self.tcn(x)
x=self.bn2(x)
out=x
if(self.if_res):
out=out+y
out=paddle.nn.functional.relu(out)
return out
class MyNet(paddle.nn.Layer):
def init(self):
super(MyNet, self).init()
self.loopnet=paddle.nn.Sequential(
LoopNet(in_channels=2,out_channels=64,if_res=0),
LoopNet(in_channels=64,out_channels=64),
LoopNet(in_channels=64,out_channels=64),
LoopNet(in_channels=64,out_channels=64),
LoopNet(in_channels=64,out_channels=128,stride=2),
LoopNet(in_channels=128,out_channels=128),
LoopNet(in_channels=128,out_channels=128),
LoopNet(in_channels=128,out_channels=256,stride=2),
LoopNet(in_channels=256,out_channels=256),
LoopNet(in_channels=256,out_channels=256)
)
self.globalpooling=paddle.nn.AdaptiveAvgPool2D(output_size=(1,1))
self.flatten=paddle.nn.Flatten()
self.fc=paddle.nn.Linear(in_features=256,out_features=30) #更改分类数目时只需更改out_features
def forward(self, x):
x=self.loopnet(x)
x=self.globalpooling(x)
x=self.flatten(x)
x=self.fc(x)
return x
7 模型训练
本项目基于PaddleVideo项目完成识别网络训练:
PaddleVideo github
PaddlePaddle-gpu==2.2.1
7.1 下载PaddleVideo代码# 进入到gitclone 的PaddleVideo目录下
%cd ~/work/
#从Github上下载PaddleVideo代码
!git clone -b release/2.1.1 https://github.com/PaddlePaddle/PaddleVideo.git
#若网速较慢,可使用如下方法下载
#!git clone -b release/2.1.1 https://hub.fastgit.org/PaddlePaddle/PaddleVideo.git# 进入到gitclone 的PaddleVideo目录下
%cd ~/work/PaddleVideo/# 检查源代码文件结构
!tree /home/aistudio/work/ -L 2
7.2 配置代码环境,安装依赖!python3.7 -m pip install --upgrade pip
!python3.7 -m pip install --upgrade -r requirements.txt
7.3 设置配置文件,完成行为识别算法训练
PaddleVideo 通过yaml配置文件的方式选择不同的算法和训练参数等,这里我们使用configs/recognition/stgcn/stgcn_fsd.yaml配置文件完成ST-GCN模型算法训练。从该配置文件中,我们可以得到如下信息:
网络结构
MODEL: framework: "RecognizerGCN" backbone: name: "STGCN" head: name: "STGCNHead" num_classes: 30
表示我们使用的是ST-GCN算法,framework为RecognizerGCN,backbone是时空图卷积网络STGCN,head使用对应的STGCNHead,数据集分类采用30分类 (用若用户使用10分类数据集,请在此更改为num_classes:10)。
数据路径
DATASET: batch_size: 32 num_workers: 4 test_batch_size: 4 test_num_workers: 0 train: format: "SkeletonDataset" file_path: "/home/aistudio/work/dataset/FSD_train_data.npy" #手动配置 label_path: "/home/aistudio/work/dataset/FSD_train_label.npy" #手动配置 test: format: "SkeletonDataset" file_path:"/home/aistudio/work/dataset/FSD_test_data.npy" # 手动配置 label_path: "/home/aistudio/work/dataset/FSD_test_label.npy" #手动配置 test_mode: True
训练数据路径通过DATASET.train.file_path字段指定,训练标签路径通过DATASET.train.label_path字段指定,测试数据路径通过DATASET.test.file_path字段指定,训练标签路径通过DATASET.teset.label_path字段指定。这四个路径需要用户在配置文件configs/recognition/stgcn/stgcn_fsd.yaml中手动配置好。本项目中路径示例如上所示。若修改为10分类训练,除了修改数据集路径之外,在上一步网络结构中需要修改num_classes。
(可以通过降低batch_size来提升实验效果,但是会加长训练时长)
数据处理
PIPELINE: train: sample: name: "Sampleframe" window_size: 350 transform: - SkeletonNorm: test: sample: name: "Sampleframe" window_size: 350 transform: - SkeletonNorm:
数据处理主要包括两步操作,分别为Sampleframe和SkeletonNorm。
优化器
OPTIMIZER: name: 'Momentum' momentum: 0.9 learning_rate: name: 'CosineAnnealingDecay' learning_rate: 0.05 T_max: 60 weight_decay: name: 'L2' value: 1e-4
网络训练使用的优化器为Momentum,学习率更新策略为CosineAnnealingDecay。
关于yaml的更多细节,可以参考PaddleVideo
7.4 训练脚本
ST-GCN模型的使用文档可参考ST-GCN基于骨骼的行为识别模型。
训练启动命令
python3.7 main.py -c configs/recognition/stgcn/stgcn_fsd.yaml
你将会看到类似如下的训练日志
[08/16 14:42:12] epoch:[ 1/60 ] train step:0 loss: 3.18299 lr: 0.050000 top1: 0.20312 top5: 0.39062 batch_cost: 1.91478 sec, reader_cost: 1.37053 sec, ips: 33.42427 instance/sec. [08/16 14:42:17] epoch:[ 1/60 ] train step:10 loss: 1.92363 lr: 0.050000 top1: 0.26562 top5: 0.90625 batch_cost: 0.49070 sec, reader_cost: 0.00027 sec, ips: 130.42598 instance/sec. [08/16 14:42:22] epoch:[ 1/60 ] train step:20 loss: 1.92695 lr: 0.050000 top1: 0.18750 top5: 0.81250 batch_cost: 0.49012 sec, reader_cost: 0.00021 sec, ips: 130.58028 instance/sec. [08/16 14:42:22] END epoch:1 train loss_avg: 2.40230 top1_avg: 0.20610 top5_avg: 0.74405 avg_batch_cost: 0.49012 sec, avg_reader_cost: 0.00021 sec, batch_cost_sum: 11.80155 sec,
注意事项
请使用GPU版本的配置环境运行本模块
训练结果保存在
PaddleVideo/output文件夹下!python3.7 main.py -c configs/recognition/stgcn/stgcn_fsd.yaml
8 模型测试
模型训练完成后,可使用测试脚本进行评估,
测试脚本启动命令
python3.7 main.py --test -c configs/recognition/stgcn/stgcn_fsd.yaml -w output/STGCN/STGCN_epoch_00200.pdparams
本案例中自带训练权重
通过
-c参数指定配置文件,通过-w指定权重存放路径进行模型测试。训练集暂未公开,公开之后可以在stgcn_fsd.yaml文件中修改训练集路径
ST-GCN模型实验精度
本案例仅选用优化后单模型ST-GCN进行试验,分别在FSD30分类与10分类的测试集下计算模型精度。模型优化策略选用了数据平均抽帧(降维),随机可学习骨骼点子图划分、通过矩阵拼接替换爱因斯坦求和约定操作。下表展示了ST-GCN模型在不同测试集下实验精度结果(单卡NVIDIA GeForce RTX 3070 Ti)
| 数据集类别 | Test Data | Top-1精度 |
|---|---|---|
| FSD30分类 | Test_A | 60.5% |
| FSD30分类 | Test_B | 58.5% |
| FSD10分类 | Test data | 91.0% |
在FSD10分类下需要修改 configs/recognition/stgcn/stgcn_fsd.yaml 文件中num_classes、batch_size等参数。通过修改参数(eg. batch_size:8,16),可以达到91%左右的测试集精度。
#通过-w参数指定模型权重进行测试
!python3.7 main.py --test -c configs/recognition/stgcn/stgcn_fsd.yaml -w output/STGCN/STGCN_epoch_00200.pdparams
9 模型导出
导出inference模型
python3.7 tools/export_model.py -c configs/recognition/stgcn/stgcn_fsd.yaml \ -p /home/aistudio/work/PaddleVideo/output/STGCN/STGCN_epoch_00200.pdparams \ #训练权重保存路径 -o /home/aistudio/work/inference/STGCN #模型输出路径
上述命令将生成预测所需的模型结构文件STGCN.pdmodel和模型权重文件STGCN.pdparams。
需要修改参数 -p和-o
各参数含义可参考模型推理方法!python3.7 tools/export_model.py -c configs/recognition/stgcn/stgcn_fsd.yaml -p /home/aistudio/work/PaddleVideo/output/STGCN/STGCN_epoch_00200.pdparams -o /home/aistudio/work/inference/STGCN
10 模型推理
python3.7 tools/predict.py --input_file /home /home/aistudio/work/dataset/example_skeleton_.npy \ --config configs/recognition/stgcn/stgcn_fsd.yaml \ --model_file /home/aistudio/work/inference/STGCN/STGCN.pdmodel \ --params_file /home/aistudio/work/inference/STGCN/STGCN.pdiparams \ --use_gpu=True \ --use_tensorrt=False
输出示例如下:
Current video file: /home/aistudio/work/dataset/example_skeleton_.npy top-1 class: 26 top-1 score: 0.8217134475708008
可以看到,使用在花样滑冰数据集上训练好的ST-GCN模型对/home/aistudio/work/dataset/example_skeleton_.npy进行预测,输出的top1类别id为26,置信度为0.8217134475708008。
!python3.7 tools/predict.py --input_file /home/aistudio/work/dataset/example_skeleton_.npy
–config configs/recognition/stgcn/stgcn_fsd.yaml
–model_file /home/aistudio/work/inference/STGCN/STGCN.pdmodel
–params_file /home/aistudio/work/inference/STGCN/STGCN.pdiparams
–use_gpu=True
–use_tensorrt=False
数据来源
本案例数据来源
FSD-10: https://paperswithcode.com/paper/fsd-10-a-dataset-for-competitive-sports
(FSD-30为FSD-10基础上扩展而来)
欢迎报名直播课加入交流群,如需更多技术交流与合作可点击以下链接
https://paddleqiyeban.wjx.cn/vj/Qlb0uS3.aspx?udsid=531417
参考文献
Spatial Temporal Graph Convolutional Networks for Skeleton-based Action Recognition, Sijie Yan, Yuanjun Xiong, Dahua Lin
FSD-10: A Dataset for Competitive Sports Content Analysis, Shenlan Liu, Xiang Liu, Gao Huang, Lin Feng, Lianyu Hu, Dong Jiang, Aibin Zhang, Yang Liu, Hong Qiao## 资源
更多资源请参考:
更多深度学习知识、产业案例,请参考:awesome-DeepLearning
更多视频模型,请参考:PaddleVideo
更多学习资料请参阅飞桨深度学习平台


 微信联系
微信联系
