1.项目概述
近期的全民热点话题离不开正在举办的冬奥会,每天都有赛场上的喜讯传来,谷爱凌夺中国第三金、武大靖和任子威的亮眼表现、苏翊鸣的“飞檐走壁”,可喜可贺!
本届冬奥会共有7个大项、15个分项和109个小项,每场比赛结束都有很多记录运动员比赛精彩瞬间的回放视频产生,这些短视频通常播放量很高,深受大众喜爱。除了服务于大众,让体育爱好者在欣赏时大饱眼福外,精彩视频剪辑技术也可以用于专业的体育训练,运动员可以通过比赛或日常训练回放来熟悉自己和对手,进行战术演练,达到知己知彼百战百胜的效果。
本项目运用动作检测技术,实现基于足球视频的高精度精彩视频剪辑方案,最终方案动作识别准确率达91%,动作检测F1-score达到76.2%。快一起来看看吧~
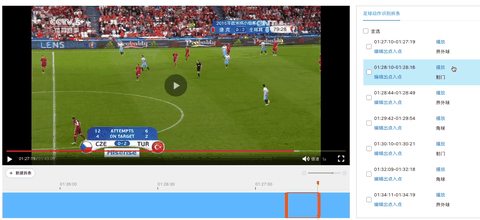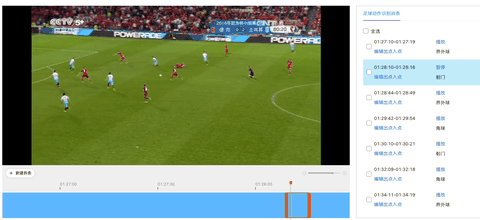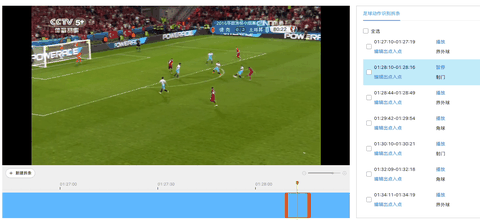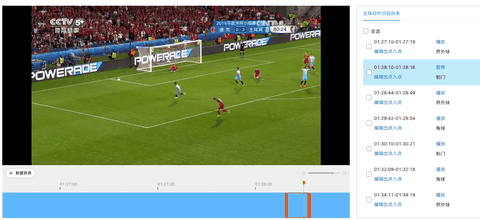
欢迎报名直播课加入交流群,如需更多技术交流与合作可点击以下链接
https://paddleqiyeban.wjx.cn/vj/Qlb0uS3.aspx?udsid=531417
2.技术难点
目前精彩视频剪辑虽然需求量大应用广泛,但人工剪辑需要浏览整个比赛视频,工作量大、成本高,又要求剪辑人员同时具有一定的体育专业知识,专业需求高。如果用AI技术来实现会存在以下两个难点问题:
动作检测任务复杂度高:视频精彩片段剪辑任务的实现要点在于准确找到该类动作发生的起止点。但体育类视频内经常包含大量冗余的背景信息,动作类别多样且持续时长相对较短,要精准的判断出动作的起始点和对应的类别,任务难度高。
视频中的信息具有多样性,如何有效利用这些特征信息也是值得我们去考虑的。
3.解决方案
动作检测任务可以理解为动作定位+识别任务,需要在一个长视频中,先定位到一个动作发生的起止点,再识别出这个动作是什么。本案例使用PP-TSM+BMN+AttentionLSTM系列模型来实现动作检测任务,具体流程如下图:
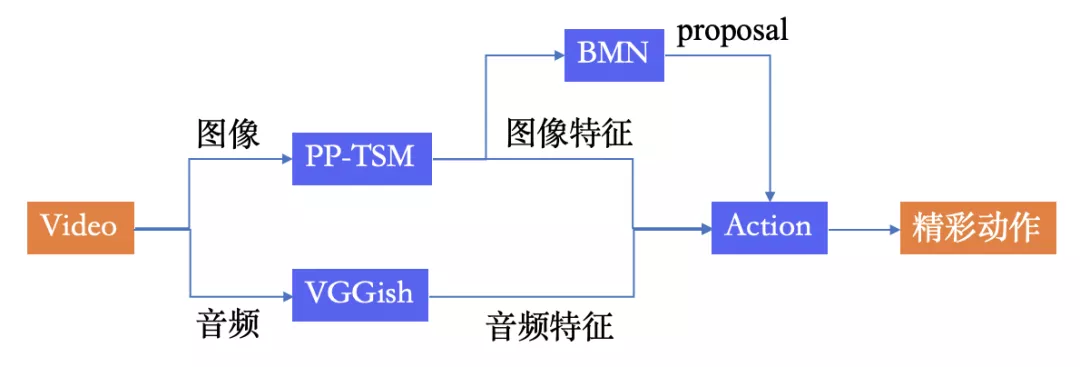
整个方案可以分为三个步骤:
使用飞桨特色的高精度视频理解模型PP-TSM提取视频图像特征;使用VGGish网络提取音频特征;
将获得的音视频特征输入BMN网络,得到由动作开始时间和结束时间组合成的时序片段(proposal);
得到时序片段提名后,根据动作开始和结束时间截断视频和音频特征,通过AttentionLSTM输出动作类别。
4.数据准备
4.1 数据集介绍
数据集由EuroCup2012, EuroCup2016, WorldCup2014,
WorldCup2018四个赛事的比赛视频组成,共计272个训练集、25个测试集,支持15种足球精彩动作定位与识别,动作类别分别为:射门、进球、进球有欢呼、角球、任意球、黄牌、红牌、点球、换人、界外球、球门球、开球、越位挥旗、回放空中对抗和回放进球。本案例中我们提供一条视频数据供大家进行测试,可以通过如下命令,下载视频。#
仅在第一次运行notebook时,执行以下命令
!wget https://bj.bcebos.com/v1/tmt-pub/datasets/EuroCup2016/63e51df254d2402fac703b6c4fdb4ea9.mp4
!mv 63e51df254d2402fac703b6c4fdb4ea9.mp4 football.mp4除视频文件外,数据集中还包含视频对应的标注文件,这里我们在PaddleVideo/applications/FootballAction/datasets/EuroCup2016 文件路径下提供了标注文件 label.json。标注格式为:
{
"fps": 5,
"gts": [
{
"url": "football.mp4",
"total_frames": 6189,
"actions": [
{
"label_ids": [
2
],
"label_names": [
"角球"
],
"start_id": 393,
"end_id": 399
},
...文件中的 fps:5 代表以每秒5帧的频率提取视频帧。actions 包含每段视频中的动作信息:动作类别标签(label_ids)、类别名称(label_names)、开始帧数(start_id)和结束帧数(end_id)。
该视频样本包含8种动作信息,动作类别标签与类别名称的对应关系如下:
"0": "背景" "1": "进球" "2": "角球" "3": "任意球" "4": "黄牌" "5": "红牌" "6": "换人" "7": "界外球"
4.2 视频采样
输入视频为mp4文件,我们提供的视频样本 football.mp4 时长1h43min。训练时如果使用全部视频文件,会消耗大量计算资源,一般预先做一些采样处理。
图像采样:以fps=5的频率抽取图像帧
音频采样:pcm音频文件,采样频率ar=16000
运行以下代码进行图像和音频采样。
移动视频football.mp4、label.json到指定位置
%cd /home/aistudio/PaddleVideo/applications/FootballAction/datasets/EuroCup2016/
!mkdir mp4
!mv /home/aistudio/football.mp4
/home/aistudio/PaddleVideo/applications/FootballAction/datasets/EuroCup2016/mp4/football.mp4#
开始运行代码前先安装好依赖
%cd /home/aistudio/PaddleVideo/
!python -m pip install -r requirements.txt -i
https://pypi.tuna.tsinghua.edu.cn/simple/抽帧时间较长,大约需要执行10分钟。%cd
/home/aistudio/PaddleVideo/applications/FootballAction
!python3.7 datasets/script/get_frames_pcm.py数据预处理后得到的文件夹格式如下:
|-- datasets # 训练数据集和处理脚本 |-- EuroCup2016 # 数据集 |-- mp4 # 原始视频.mp4 |-- frames # 图像帧 |-- pcm # 音频pcm |-- url.list # 视频列表 |-- label.json # 视频原始gts
5. 模型训练
5.1 PP-TSM训练
5.1.1 PP-TSM 训练数据处理
PP-TSM模型是一个视频理解模型,它可以用于包含单动作的视频段的视频分类任务。在本方案中,我们使用训练好的PP-TSM模型提取视频图像特征。
get_instance_for_pptsm.py 文件用于生成训练所需的正负样本。正样本为标注后的运动区间,该区间内的所有图像帧会生成一个pkl文件;负样本为标注后的非运动区间,因为足球赛事中无特殊动作的时间较长,负样本以随机取N个区间生成N个pkl的方式生成。
!python datasets/script/get_instance_for_pptsm.py完成该步骤后,数据存储位置如下:
|-- datasets # 训练数据集和处理脚本 |-- EuroCup2016 # 数据集 |-- input_for_pptsm # pptsm训练的数据
5.1.2 PP-TSM模型训练
在训练开始前,需要先下载图像蒸馏预训练模型ResNet50_vd_ssld_v2.pdparams 作为模型 backbone 初始化参数,通过如下命令下载:# 在第一次运行代码时执行如下命令
!wget https://videotag.bj.bcebos.com/PaddleVideo/PretrainModel/ResNet50_vd_ssld_v2_pretrained.pdparams
!mkdir pretrain
!mv ResNet50_vd_ssld_v2_pretrained.pdparams pretrain/ResNet50_vd_ssld_v2_pretrained.pdparams启动训练,可以在 pptsm_football_v2.0.yaml 中调节训练参数。# 启动训练
%cd /home/aistudio/PaddleVideo/
!python -B -m paddle.distributed.launch
–gpus=“0”
–log_dir=applications/FootballAction/train_pptsm/logs
main.py
–validate
-c applications/FootballAction/train_proposal/configs/pptsm_football_v2.0.yaml
-o output_dir=applications/FootballAction/train_pptsm/
5.1.3 PP-TSM模型转为预测模式
使用如下命令生成预测所需的模型结构文件ppTSM.pdmodel和模型权重文件ppTSM.pdiparams。
!python tools/export_model.py -c applications/FootballAction/train_proposal/configs/pptsm_football_v2.0.yaml
-p applications/FootballAction/train_pptsm/ppTSM_best.pdparams
-o applications/FootballAction/checkpoints/ppTSM
5.1.4 基于PP-TSM的视频特征提取
基于刚训练好的PP-TSM模型提取视频特征。每次输入8帧图像,输出8维特征,最后将所有特征拼接在一起代表视频特征。
extract_feat.py 文件同时进行视频图像特征和音频特征提取,音频特征通过VGGish模型提取。该模型权重文件可通过如下命令下载:# 仅在第一次运行notebook时下载
!wget https://videotag.bj.bcebos.com/PaddleVideo-release2.1/FootballAction/audio.tar
!tar -xvf audio.tar
!rm audio.tar
!mv AUDIO/
/home/aistudio/PaddleVideo/applications/FootballAction/checkpoints/提取视频图像和音频特征:%cd
/home/aistudio/PaddleVideo/applications/FootballAction/extractor
!python extract_feat.py特征提取完成后存储在EuroCup2016文件夹下
|-- datasets # 训练数据集和处理脚本 |-- EuroCup2016 # 数据集 |-- features # 视频的图像+音频特征
5.2 BMN训练
将得到的音视频特征整合输入BMN网络,得到由动作开始时间和结束时间组合成的时序片段(proposal)。
5.2.1 BMN训练数据处理
get_instance_for_bmn 文件用于提取二分类的proposal,根据标注文件和音视频特征得到BMN所需要的数据集。%cd /home/aistudio/PaddleVideo/applications/FootballAction
!python datasets/script/get_instance_for_bmn.py得到的数据格式如下:
duration_second 代表视频片段时长,duration_frame 代表涵盖多少帧,annotations为这段视频的真实标注,segment为动作起止时间,label及label_name 为动作类别和名称。
{
"719b0a4bcb1f461eabb152298406b861_753_793": {
"duration_second": 40.0,
"duration_frame": 200,
"feature_frame": 200,
"subset": "train",
"annotations": [
{
"segment": [
15.0,
22.0
],
"label": "3.0",
"label_name": "任意球"
}
]
},
...
}完成该步骤后,数据存储位置如下:
|-- datasets # 训练数据集和处理脚本 |-- EuroCup2016 # xx数据集 |-- input_for_bmn # bmn训练的proposal
5.2.2 BMN模型训练
该步骤训练与PP-TSM模型训练类似,可以调整 bmn_football_v2.0.yaml 文件,修改训练参数。%cd /home/aistudio/PaddleVideo/
!python -B -m paddle.distributed.launch
–gpus=‘0’
–log_dir=applications/FootballAction/train_bmn/logs
main.py
–validate
-c applications/FootballAction/train_proposal/configs/bmn_football_v2.0.yaml
-o output_dir=applications/FootballAction/train_bmn/
5.2.3 BMN模型转为预测模式
生成预测所需的模型结构文件BMN.pdmodel和模型权重文件BMN.pdiparams。!python tools/export_model.py
-c applications/FootballAction/train_proposal/configs/bmn_football_v2.0.yaml
-p applications/FootballAction/train_bmn/BMN_epoch_00001.pdparams
-o applications/FootballAction/checkpoints/BMN
5.2.4 BMN模型预测
进行模型预测,得到动作proposal的信息,包括动作开始时间、结束时间以及置信度。%cd /home/aistudio/PaddleVideo/applications/FootballAction/extractor
!python extract_bmn.py完成该步骤后,数据存储位置
|-- datasets # 训练数据集和处理脚本 |-- EuroCup2016 # xx数据集 |-- feature_bmn |-- prop.json # bmn 预测结果
5.3 LSTM训练
得到时序片段提名(proposal)后,根据动作开始和结束时间阶段视频和音频特征,通过AttentionLSTM输出动作类别。
5.3.1 LSTM训练数据处理
按照BMN预测到的proposal截断视频特征,生成训练AttentionLSTM所需数据集。
%cd /home/aistudio/PaddleVideo/applications/FootballAction/datasets/script/
!python get_instance_for_lstm.py
5.3.2 LSTM训练
通过如下命令训练AttentionLSTM网络。
cd /home/aistudio/PaddleVideo/applications/FootballAction/train_lstm/ python -u scenario_lib/train.py \ --model_name=ActionNet \ --config=conf/conf.txt \ --save_dir=../football_lstm
这里因为训练数据只提供了一条视频,直接进行LSTM训练会存在问题,如有需要可根据自己的数据集使用上述命令进行训练,并通过修改 conf/conf.txt 文件,更改模型参数。
5.3.3 LSTM模型转为预测模式
如需将训练模型转为预测模式,可通过以下命令生成模型结构文件。
cd /home/aistudio/PaddleVideo/applications/FootballAction/train_lstm/ python inference_model.py --config=conf/conf.yaml --weights=../football_lstm/ActionNet.pdparams --save_dir=../checkpoints/LSTM
我们提供训练好的LSTM模型,共大家进行后续测试。!wget https://videotag.bj.bcebos.com/PaddleVideo-release2.1/FootballAction/lstm.tar
!tar -xvf lstm.tar
!rm lstm.tar
!mv LSTM/ /home/aistudio/PaddleVideo/applications/FootballAction/checkpoints/
6. 模型推理
输入一条视频数据,以该网络结构进行推理。%cd /home/aistudio/PaddleVideo/applications/FootballAction/predict
!python predict.py
7. 模型评估
通过如下命令开始模型评估。# 包括bmn proposal 评估和最终action评估
%cd /home/aistudio/PaddleVideo/applications/FootballAction/predict
!python eval.py results.json
8. 模型优化
本案例中展示的PP-TSM+BMN+AttentionLSTM的实现方案是经过多次优化实验得来的。在实验的初始阶段,我们最先选取的是TSN+BMN+AttentionLSTM的实现方案。后续经过三个方面的大量优化处理,才在模型效果提升方面有了显著成果。可以通过阅读本节获得在模型效果提升方面的宝贵经验。
实验分为以下三个方面:
更换图像特征提取模型,分别采用视频理解模型TSN、TSM、PP-TSM 进行实验,在动作识别任务上精度更高的模型,在动作检测任务上也有更好的表现。
在BMN生成的时序提名基础上扩展proposal特征,更好的涵盖整个动作特征
增加训练数据量,使网络具有更好的泛化能力
实验最初采用TSN+BMN+AttentionLSTM的解决方案。实验baseline如下:
| 图像特征提取模型 | top1 acc | 时序提名生成 | 序列分类 | precision | recall | F1-score |
|---|---|---|---|---|---|---|
| TSN | 75.86 | BMN | LSTM | 60.04 | 61.31 | 60.67 |
通过将TSN更换为在视频理解任务上精度更好的TSM模型得到如下效果提升:
| 图像特征提取模型 | top1 acc | 时序提名生成 | 序列分类 | precision | recall | F1-score |
|---|---|---|---|---|---|---|
| TSN | 75.86 | BMN | LSTM | 60.04 | 61.31 | 60.67 |
| TSM | 90.24 | BMN | LSTM | 71.06 | 65.93 | 68.4 |
可以看到,TSN和TSM模型在视频分类任务上的精度分别是75.86%和90.24%,精度大幅提升,使得提取的视频图像特征更为准确,最终在行为检测任务上F1-score由60.67%提升到68.4%。
可以通过如下代码训练TSN、TSM网络,进行数据对比。
#训练TSN
%cd /home/aistudio/PaddleVideo/
!python -B -m paddle.distributed.launch
–gpus=“0”
–log_dir=applications/FootballAction/train_tsn/logs
main.py
–validate
-c applications/FootballAction/train_proposal/configs/tsn_football.yaml
-o output_dir=applications/FootballAction/train_tsn/# 训练TSM
%cd /home/aistudio/PaddleVideo/
!python -B -m paddle.distributed.launch
–gpus=“0”
–log_dir=applications/FootballAction/train_tsm/logs
main.py
–validate
-c applications/FootballAction/train_proposal/configs/tsm_football.yaml
-o
output_dir=applications/FootballAction/train_tsm/除此之外,我们还查验了BMN生成的proposals,发现某些时间片段并不能完整涵盖动作。为更好的涵盖整个动作特征,我们将生成的proposal前后各扩展1s。
实验对比数据如下:
| 图像特征提取模型 | top1 acc | 时序提名生成 | 序列分类 | precision | recall | F1-score |
|---|---|---|---|---|---|---|
| TSM | 90.24 | BMN | LSTM | 71.06 | 65.93 | 68.4 |
| TSM | 90.24 | BMN | LSTM + 扩展全部动作的proposal | 80.3 | 66.31 | 72.64 |
对所有动作扩展proposal后我们发现,并不是所有动作扩展proposal特征都有明显的正向提升,因此我们选择只对部分特征扩展proposal,得到如下实验结果:
| 图像特征提取模型 | top1 acc | 时序提名生成 | 序列分类 | precision | recall | F1-score |
|---|---|---|---|---|---|---|
| TSM | 90.24 | BMN | LSTM + 扩展全部动作的proposal | 80.3 | 66.31 | 72.64 |
| TSM | 90.24 | BMN | LSTM + 扩展部分动作的proposal | 79.37 | 67.76 | 73.1 |
可通过以下代码扩展proposal特征:
%cd /home/aistudio/PaddleVideo/applications/FootballAction/datasets/script/
!python
get_instance_for_lstm_long_proposal.py以上所有实验均基于由156个训练集+15个测试集组成的数据集,经过一轮新的数据标注,我们将数据集扩充为272训练集+25测试集,并基于此进行了新的训练,得到如下结果:
| 图像特征提取模型 | top1 acc | 时序提名生成 | 序列分类 | precision | recall | F1-score |
|---|---|---|---|---|---|---|
| TSM | 90.24 | BMN | LSTM + 扩展部分动作的proposal | 79.37 | 67.76 | 73.1 |
| TSM + 数据扩展 | 90.85 | BMN | LSTM + 扩展部分动作的proposal | 80.22 | 68.72 | 74.03 |
最后,我们将TSM模型更换为精度更高的PP-TSM模型,得到最终的实验结果。
| 图像特征提取模型 | top1 acc | 时序提名生成 | 序列分类 | precision | recall | F1-score |
|---|---|---|---|---|---|---|
| TSM + 数据扩展 | 90.85 | BMN | LSTM + 扩展部分动作的proposal | 80.22 | 68.72 | 74.03 |
| PP-TSM + 数据扩展 | 91.03 | BMN | LSTM + 扩展部分动作的proposal | 81.2 | 71.8 | 76.2 |
以上所有实验的对比数据如下:
| 图像特征提取模型 | top1 acc | 时序提名生成 | 序列分类 | precision | recall | F1-score |
|---|---|---|---|---|---|---|
| TSN | 75.86 | BMN | LSTM | 60.04 | 61.31 | 60.67 |
| TSM | 90.24 | BMN | LSTM | 71.06 | 65.93 | 68.4 |
| TSM | 90.24 | BMN | LSTM + 扩展全部动作的proposal | 80.3 | 66.31 | 72.64 |
| TSM | 90.24 | BMN | LSTM + 扩展部分动作的proposal | 79.37 | 67.76 | 73.1 |
| TSM + 数据扩展 | 90.85 | BMN | LSTM + 扩展部分动作的proposal | 80.22 | 68.72 | 74.03 |
| PP-TSM + 数据扩展 | 91.03 | BMN | LSTM + 扩展部分动作的proposal | 81.2 | 71.8 | 76.2 |
https://paddleqiyeban.wjx.cn/vj/Qlb0uS3.aspx?udsid=531417
参考文献
Tianwei Lin, Xiao Liu, Xin Li, Errui Ding, Shilei Wen,2019. BMN: Boundary-Matching Network for Temporal Action Proposal Generation. https://arxiv.org/pdf/1907.09702.pdf
资源
更多资源请参考:
更多深度学习知识、产业案例,请参考:awesome-DeepLearning
更多动作识别、动作检测、多模态、视频目标分割、单目深度估计模型,请参考:PaddleVideo
更多学习资料请参阅 飞桨深度学习平台


 微信联系
微信联系
