1、项目说明
智能问答是获取信息和知识的更直接、更高效的方式之一,传统的信息检索方法智能找到相关的文档,而智能问答能够直接找到精准的答案,极大的节省了人们查询信息的时间。问答按照技术分为基于阅读理解的问答和检索式的问答,阅读理解的问答是在正文中找到对应的答案片段,检索式问答则是匹配高频的问题,然后把答案返回给用户。本项目属于检索式的问答,问答的领域用途很广,比如搜索引擎,小度音响等智能硬件,政府,金融,银行,电信,电商领域的智能客服,聊天机器人等。下图是保险领域的问答示例:
本项目基于PaddleNLP FAQ_Finance。
本项目源代码全部开源在 PaddleNLP 中。
如果对您有帮助,欢迎star收藏一下,不易走丢哦~链接指路:https://github.com/PaddlePaddle/PaddleNLP

加入微信交流群,一起学习吧
欢迎扫码加入产业应用技术交流群(微信),一起交流NLP在金融行业实践技术:

1.1 应用特色
低门槛
手把手搭建检索式 FAQ System
无需相似 Query-Query Pair 标注数据也能构建 FAQ System
效果好
业界领先的检索预训练模型: RocketQA DualEncoder
针对无标注数据场景的领先解决方案: 检索预训练模型 + 增强的无监督语义索引微调
性能快
基于 Paddle Inference 快速抽取向量
基于 Milvus 快速查询和高性能建库
基于 Paddle Serving 高性能部署
1.2 问答流程设计
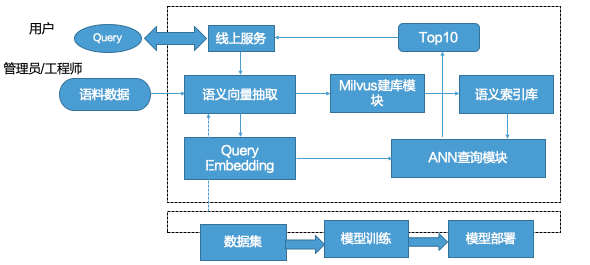
问答的流程分为两部分,第一部分是管理员/工程师流程,第二部分就是用户使用流程,在模型的层面,需要离线的准备数据集,训练模型,然后把训练好的模型部署上线。另外,就是线上搭建问答检索引擎,第一步把收集好的语料数据,利用训练好的模型抽取问题的向量,然后把向量插入到近似向量检索引擎中,构建语义索引库,这部分做完了之后,就可以使用这个问答服务了,但是用户输入了Query之后,发生了什么呢?第一步就是线上服务会接收Query后,对数据进行处理,并抽取用户Query的向量,然后在ANN查询模块进行检索匹配相近的问题,最终选取Top10条数据,返回给线上服务,线上服务经过一定的处理,把最终的答案呈现给用户。
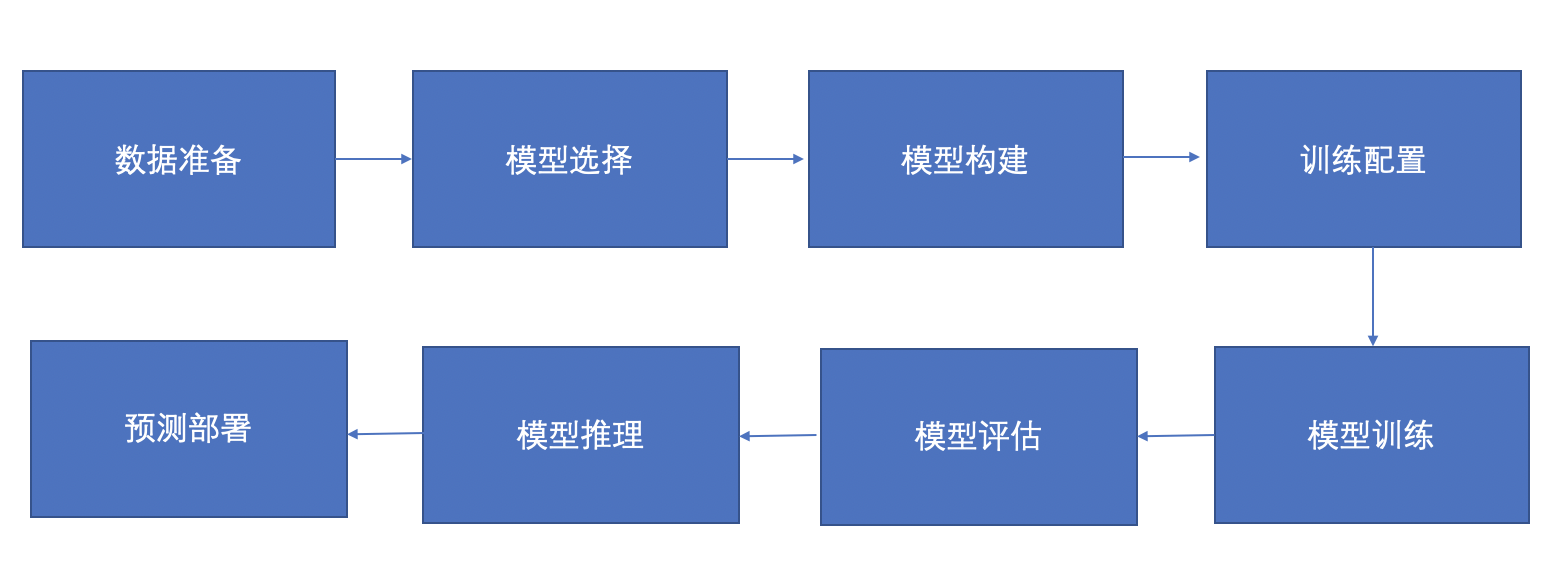
本次模型的优化流程如下:
2、安装说明
AI Studio平台默认安装了Paddle和PaddleNLP,并定期更新版本。 如需手动更新,可参考如下说明:# 首次更新完以后,重启后方能生效
!pip install --upgrade paddlenlp安装项目依赖的其他库:
备注:如果提示找不到相关文件,左上角刷新即可。!pip install -r requirements.txt首先导入项目所需要的第三方库:# 加载系统的API
import abc
import sys
from functools import partial
import argparse
import os
import random
import time
import numpy as np
#加载飞桨的API
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle import inference
#加载PaddleNLP的API
import paddlenlp as ppnlp
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.datasets import load_dataset, MapDataset
from paddlenlp.transformers import LinearDecayWithWarmup
from paddlenlp.utils.downloader import get_path_from_url
import paddle_serving_client.io as serving_io
3、数据准备
基于Github上公开的保险问答数据集,我们需要准备训练集,评估集和召回库三部分。首先保险的数据包含Query,Title,Reply等字段,我们选取其中的Query和Reply字段来构建问答系统。
Github的地址为:保险
【免责声明】:数据集是基于Github开源数据进行了处理得到的,如果有任何侵权问题,请及时联系,我们会在第一时间进行删除处理。
有需要的同学去改地址下载数据即可。
接下来我们构造训练集,训练集则直接使用保险数据中的Query,然后为了优化效果,我们使用同义词替换的方法构造同义句,构造的同义句如下:
训练集示例如下:
我儿子还在念小学,适不适合投保康惠保呢? 被骄车撞成右膀肱骨粉碎性骨折保守治疗怎么向车主和他的保险公司索赔 商业医疗保险报销程序? 家里有社保,还有必要买重疾险吗? 工地买了建工险,出了事故多长时间上报保险公司有效 请问下哆啦a保值不值得买呢?不晓得保障多不多
利用同义词替换的方法生成的训练集如下:
我儿子还在念小学,适不适合投保康惠保呢? 我儿子还在念小学校,适不适合投保康惠保呢? 被骄车撞成右膀肱骨粉碎性骨折保守治疗怎么向车主和他的保险公司索赔 被骄车撞成右膀肱骨粉碎性骨折保守诊疗怎么向车主和他的保险公司索赔 商业医疗保险报销程序? 买卖医疗保险报销程序? 家里有社保,还有必要买重疾险吗? 家里有社保,再有必要买重疾险吗? 工地买了建工险,出了事故多长时间上报保险公司有效 工地买了建工险,出了事故多长时间上报保险公司管事
用中英文回译的方法来生成评估集合,评估集是问题对,示例如下:
企业养老保险自己怎么办理 如何办理企业养老保险 西*牙签证保险怎么买? 如何为西班牙购买签证保险? 康惠保的保额要买到多少才合适? 康慧宝需要买多少? 车辆事故对方全责维修费不肯垫付怎么办 如果另一方对车辆事故负有全部责任,并且拒绝提前支付维修费,该怎么办 准备清明节去新*坡旅行,哪款旅游险好? 准备清明节去新兴坡旅游,什么样的旅游保险好?
3.1 加载数据
加载数据集,可以选择train.csv或者train_aug.csv,train.csv表示的是无监督数据集,train_aug.csv表示的是同义词替换的数据集,可以二选一。from data import read_text_pair
def read_simcse_text(data_path):
“”“Reads data.”""
with open(data_path, ‘r’, encoding=‘utf-8’) as f:
for line in f:
data = line.rstrip()
# 无监督训练,text_a和text_b是一样的
yield {‘text_a’: data, ‘text_b’: data}
#加载训练集, 无监督
#train_set_file=‘baoxian/train.csv’
#train_ds = load_dataset(read_simcse_text, data_path=train_set_file, lazy=False)
#加载数据集,数据增强:
train_set_file=‘baoxian/train_aug.csv’
train_ds = load_dataset(read_text_pair, data_path=train_set_file, lazy=False)
#输出三条数据
for i in range(3):
print(train_ds[i])打印结果可以看出,无监督数据:输入数据的两条文本是一样的。对于增强后的数据,两条文本是不一样的,可以比较一下差别。无监督数据读取使用read_simcse_text,增强的数据读取使用read_text_pair。
3.2 构建Dataloader
def convert_example(example, tokenizer, max_seq_length=512, do_evalute=False):
# 把文本转换成id的形式
result = []
for key, text in example.items(): if 'label' in key: # do_evaluate result += [example['label']] else: # do_train encoded_inputs = tokenizer(text=text, max_seq_len=max_seq_length) input_ids = encoded_inputs["input_ids"] token_type_ids = encoded_inputs["token_type_ids"] result += [input_ids, token_type_ids] return result
#序列的最大的长度,根据数据集的情况进行设置
max_seq_length=64
#batch_size越大,效果会更好
batch_size=64
#使用rocketqa开放领域的问答模型
model_name_or_path=‘rocketqa-zh-dureader-query-encoder’
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained(model_name_or_path)
#partial赋默认的值
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
#对齐组装成小批次数据
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # query_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # query_segment
Pad(axis=0, pad_val=tokenizer.pad_token_id), # title_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # tilte_segment
): [data for data in fn(samples)]# 明文数据 -> ID 序列训练数据
def create_dataloader(dataset,
mode=‘train’,
batch_size=1,
batchify_fn=None,
trans_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False if mode == 'train': batch_sampler = paddle.io.DistributedBatchSampler( dataset, batch_size=batch_size, shuffle=shuffle) else: batch_sampler = paddle.io.BatchSampler( dataset, batch_size=batch_size, shuffle=shuffle) return paddle.io.DataLoader( dataset=dataset, batch_sampler=batch_sampler, collate_fn=batchify_fn, return_list=True)
#构建训练的Dataloader
train_data_loader = create_dataloader(
train_ds,
mode=‘train’,
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
#展示一下输入的dataloader的数据
for idx, batch in enumerate(train_data_loader):
if idx == 0:
print(batch)
break
上面展示的是一个batch的数据,包含两个Tensor,第一个Tensor表示的是input_ids,第二个Tensor表示的是token_type_ids;第一个Tensor中,32是batch_size的维度,44代表的是序列的长度,表示输入的文本的最大长度是44;第二个Tensor中,32表示的也是batch_size,44表示的是序列的长度。
4、模型选择
首先保险问答场景的数据只有问题和答案对,再没有其他的数据了。如果使用有监督方法,需要问题-问题对,还需要收集一些问题进行人工标注。因此可以考虑使用无监督语义索引技术SimCSE模型。
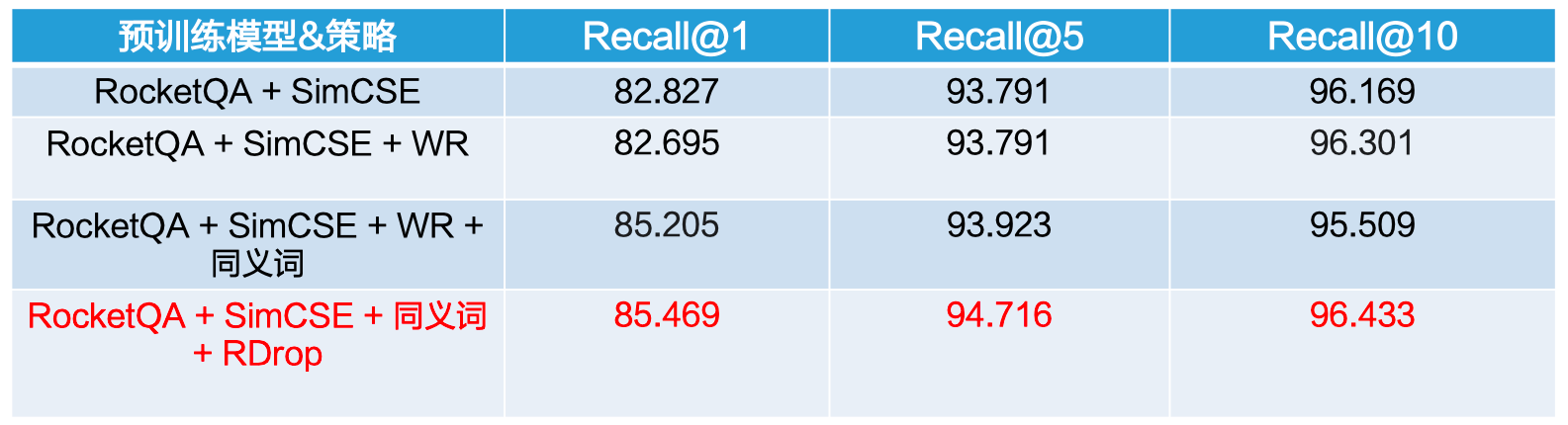
总体上无监督技术没有有监督技术效果好,所以为了提升SimCSE的性能,我们使用了开放问答领域的预训练语言模型RocketQA,并且在SimCSE的基础上利用WR,R-Drop等策略进行优化。
4.1 模型方案设计
无监督方案
第一步:基于检索式问答SOTA预训练模型RocketQA
第二步:无监督训练策略SimCSE
第三步:无监督增强策略Word Reptition, WR, RDrop
整个方案无需人工参与数据标注,所以是一个无监督的解决方案。
5、模型构建
5.1 SimCSE模型
搭建SimCSE模型,主要部分是用query和title分别得到embedding向量,然后计算余弦相似度。
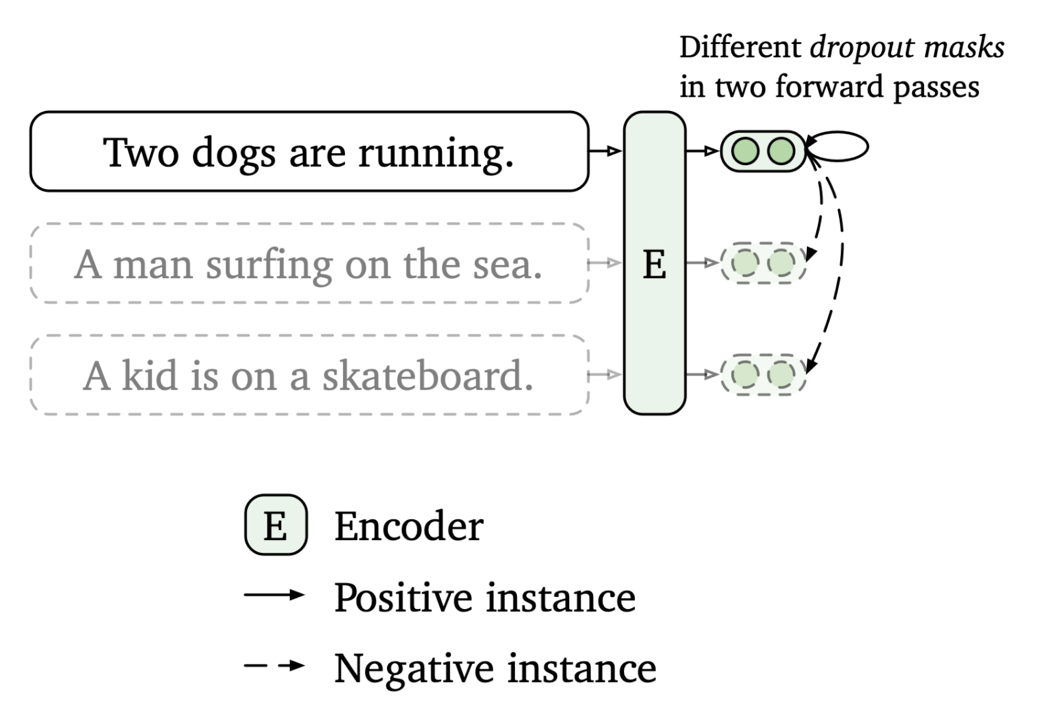
上图是SimCSE的原理图,SimCSE主要是通过dropout来把同一个句子变成正样本(做两次前向,但是dropout有随机因素,所以产生的向量不一样,但是本质上还是表示的是同一句话),把一个batch里面其他的句子变成负样本的。
SimCSE网络结构搭建,搭建代码如下:class SimCSE(nn.Layer):
def init(self,
pretrained_model,
dropout=None,
margin=0.0,
scale=20,
output_emb_size=None):
super().__init__() self.ptm = pretrained_model # 显式的加一个dropout来控制 self.dropout = nn.Dropout(dropout if dropout is not None else 0.1) # 考虑到性能和效率,我们推荐把output_emb_size设置成256 # 向量越大,语义信息越丰富,但消耗资源越多 self.output_emb_size = output_emb_size if output_emb_size > 0: weight_attr = paddle.ParamAttr( initializer=paddle.nn.initializer.TruncatedNormal(std=0.02)) self.emb_reduce_linear = paddle.nn.Linear( 768, output_emb_size, weight_attr=weight_attr) self.margin = margin # 为了使余弦相似度更容易收敛,我们选择把计算出来的余弦相似度扩大scale倍,一般设置成20左右 self.sacle = scale # 二分类计算 self.classifier = nn.Linear(output_emb_size, 2) # R-Drop的损失 self.rdrop_loss = ppnlp.losses.RDropLoss() # 加入jit注释能够把该提取向量的函数导出成静态图 # 对应input_id,token_type_id两个 @paddle.jit.to_static(input_spec=[ paddle.static.InputSpec( shape=[None, None], dtype='int64'), paddle.static.InputSpec( shape=[None, None], dtype='int64') ]) def get_pooled_embedding(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None, with_pooler=True): # Note: cls_embedding is poolerd embedding with act tanh sequence_output, cls_embedding = self.ptm(input_ids, token_type_ids, position_ids, attention_mask) if with_pooler == False: cls_embedding = sequence_output[:, 0, :] if self.output_emb_size > 0: cls_embedding = self.emb_reduce_linear(cls_embedding) cls_embedding = self.dropout(cls_embedding) cls_embedding = F.normalize(cls_embedding, p=2, axis=-1) return cls_embedding def get_semantic_embedding(self, data_loader): self.eval() with paddle.no_grad(): for batch_data in data_loader: input_ids, token_type_ids = batch_data input_ids = paddle.to_tensor(input_ids) token_type_ids = paddle.to_tensor(token_type_ids) text_embeddings = self.get_pooled_embedding( input_ids, token_type_ids=token_type_ids) yield text_embeddings def cosine_sim(self, query_input_ids, title_input_ids, query_token_type_ids=None, query_position_ids=None, query_attention_mask=None, title_token_type_ids=None, title_position_ids=None, title_attention_mask=None, with_pooler=True): query_cls_embedding = self.get_pooled_embedding( query_input_ids, query_token_type_ids, query_position_ids, query_attention_mask, with_pooler=with_pooler) title_cls_embedding = self.get_pooled_embedding( title_input_ids, title_token_type_ids, title_position_ids, title_attention_mask, with_pooler=with_pooler) cosine_sim = paddle.sum(query_cls_embedding * title_cls_embedding, axis=-1) return cosine_sim def forward(self, query_input_ids, title_input_ids, query_token_type_ids=None, query_position_ids=None, query_attention_mask=None, title_token_type_ids=None, title_position_ids=None, title_attention_mask=None): # 第 1 次编码: 文本经过无监督语义索引模型编码后的语义向量 # [N, output_emb_size] query_cls_embedding = self.get_pooled_embedding( query_input_ids, query_token_type_ids, query_position_ids, query_attention_mask) # 第 2 次编码: 文本经过无监督语义索引模型编码后的语义向量 # [N, output_emb_size] title_cls_embedding = self.get_pooled_embedding( title_input_ids, title_token_type_ids, title_position_ids, title_attention_mask) # 使用R-Drop logits1=self.classifier(query_cls_embedding) logits2 = self.classifier(title_cls_embedding) kl_loss = self.rdrop_loss(logits1, logits2) # 相似度矩阵: [N, N] cosine_sim = paddle.matmul( query_cls_embedding, title_cls_embedding, transpose_y=True) # substract margin from all positive samples cosine_sim() # 填充self.margin值,比如margin为0.2,query_cls_embedding.shape[0]=2 # margin_diag: [0.2,0.2] margin_diag = paddle.full( shape=[query_cls_embedding.shape[0]], fill_value=self.margin, dtype=paddle.get_default_dtype()) # input paddle.diag(margin_diag): [[0.2,0],[0,0.2]] # input cosine_sim : [[1.0,0.6],[0.6,1.0]] # output cosine_sim: [[0.8,0.6],[0.6,0.8]] cosine_sim = cosine_sim - paddle.diag(margin_diag) # scale cosine to ease training converge cosine_sim *= self.sacle # 转化成分类任务: 对角线元素是正例,其余元素为负例 # labels : [0,1,2,3] labels = paddle.arange(0, query_cls_embedding.shape[0], dtype='int64') # labels : [[0],[1],[2],[3]] labels = paddle.reshape(labels, shape=[-1, 1]) # 交叉熵损失函数 loss = F.cross_entropy(input=cosine_sim, label=labels) return loss, kl_loss
5.2 模型优化策略
5.2.1 WR 策略
| 策略 | 举例 | 解释 |
|---|---|---|
| 原句 | 企业养老保险自己怎么办理 | - |
| WR策略(Yes) | 企业养老老保险自己怎么么办理 | 语义改变较小 |
| 随机插入(No) | 无企业养老保险自己怎么办理 | 语义改变较大 |
| 随机删除(No) | 企业养保险自己怎么办理 | 语义改变较大 |
上图是WR策略跟其他策略的简单比较,其中WR策略对原句的语义改变很小,但是改变了句子的长度,破除了SimCSE句子长度相等的假设。WR策略起源于ESimCSE的论文,有兴趣可以从论文里了解其原理。def
word_repetition(input_ids, token_type_ids, dup_rate=0.32):
“”“Word Reptition strategy.”""
input_ids = input_ids.numpy().tolist()
token_type_ids = token_type_ids.numpy().tolist()
batch_size, seq_len = len(input_ids), len(input_ids[0]) repetitied_input_ids = [] repetitied_token_type_ids = [] rep_seq_len = seq_len for batch_id in range(batch_size): cur_input_id = input_ids[batch_id] actual_len = np.count_nonzero(cur_input_id) dup_word_index = [] # If sequence length is less than 5, skip it if (actual_len > 5): dup_len = random.randint(a=0, b=max(2, int(dup_rate * actual_len))) # Skip cls and sep position dup_word_index = random.sample( list(range(1, actual_len - 1)), k=dup_len) r_input_id = [] r_token_type_id = [] for idx, word_id in enumerate(cur_input_id): # Insert duplicate word if idx in dup_word_index: r_input_id.append(word_id) r_token_type_id.append(token_type_ids[batch_id][idx]) r_input_id.append(word_id) r_token_type_id.append(token_type_ids[batch_id][idx]) after_dup_len = len(r_input_id) repetitied_input_ids.append(r_input_id) repetitied_token_type_ids.append(r_token_type_id) if after_dup_len > rep_seq_len: rep_seq_len = after_dup_len # Padding the data to the same length for batch_id in range(batch_size): after_dup_len = len(repetitied_input_ids[batch_id]) pad_len = rep_seq_len - after_dup_len repetitied_input_ids[batch_id] += [0] * pad_len repetitied_token_type_ids[batch_id] += [0] * pad_len return paddle.to_tensor(repetitied_input_ids), paddle.to_tensor( repetitied_token_type_ids)
5.2.2 R-Drop策略
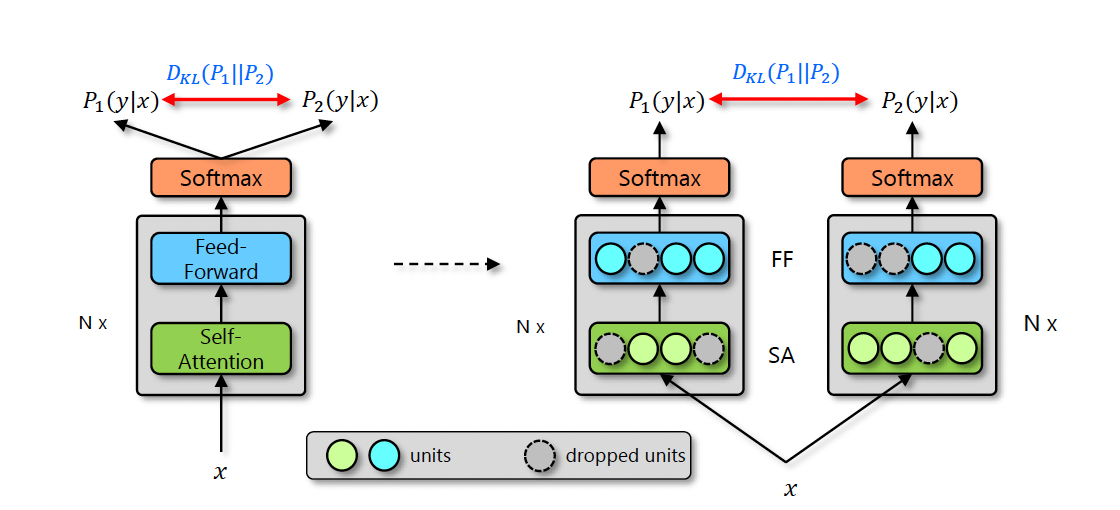
R-Drop的原理:为了避免过拟合,通常会加入Dropout等较为成熟的正则话策略,即同样的输入,分别用模型预测两次,因为有Dropout的存在,所以会得到两个不同分布的输出,可以近似的看作两个不同的模型的网络的输出。我们用P1和P2表示模型输出的两个不同分布,R-Drop的目的就是在训练的过程中不断拉低这两个分布之间的KL散度。
R-Drop的API请参考:https://paddlenlp.readthedocs.io/zh/latest/source/paddlenlp.losses.rdrop.html
6.训练配置
训练配置包括一些超参数,优化器,模型实例化等设置。# 关键参数
scale=20 # 推荐值: 10 ~ 30
margin=0.1 # 推荐值: 0.0 ~ 0.2
epochs= 3
#学习率设置
learning_rate=5E-5
warmup_proportion=0.0
weight_decay=0.0
save_steps=10
#可以根据实际情况进行设置
output_emb_size=256
dup_rate=0.3 # 建议设置在0~0.3之间
save_dir=‘checkpoints’# 使用预训练模型
pretrained_model = ppnlp.transformers.ErnieModel.from_pretrained(model_name_or_path)
#无监督+R-Drop,类似于多任务学习
model = SimCSE(
pretrained_model,
margin=margin,
scale=scale,
output_emb_size=output_emb_size)
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps,
warmup_proportion)
#Generate parameter names needed to perform weight decay.
#All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in [“bias”, “norm”])
]
#AdamW优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
7. 模型训练
训练过程是从train_data_loader中不断得到小批次的数据,然后送入模型预测得到损失,然后反向更新梯度,代码如下:def do_train(model,train_data_loader,**kwargs):
save_dir=kwargs[‘save_dir’]
global_step = 0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
query_input_ids, query_token_type_ids, title_input_ids, title_token_type_ids = batch
# sample的方式使用同义词语句和WR策略
# 概率可以设置
if(random.random()<0.2):
title_input_ids,title_token_type_ids=query_input_ids,query_token_type_ids
query_input_ids,query_token_type_ids=word_repetition(query_input_ids,query_token_type_ids,dup_rate)
title_input_ids,title_token_type_ids=word_repetition(title_input_ids,title_token_type_ids,dup_rate)
# else:
# query_input_ids,query_token_type_ids=word_repetition(query_input_ids,query_token_type_ids,dup_rate)
# title_input_ids,title_token_type_ids=word_repetition(title_input_ids,title_token_type_ids,dup_rate)
loss, kl_loss = model( query_input_ids=query_input_ids, title_input_ids=title_input_ids, query_token_type_ids=query_token_type_ids, title_token_type_ids=title_token_type_ids) # 加入R-Drop的损失优化,默认设置的是0.1,参数可以调 loss = loss + kl_loss * 0.1 # 每隔5个step打印日志 global_step += 1 if global_step % 5 == 0: print( "global step %d, epoch: %d, batch: %d, loss: %.5f, speed: %.2f step/s" % (global_step, epoch, step, loss, 10 / (time.time() - tic_train))) tic_train = time.time() # 反向梯度求导更新 loss.backward() optimizer.step() lr_scheduler.step() optimizer.clear_grad() # 每隔save_steps保存模型 if global_step % save_steps == 0: save_path = os.path.join(save_dir, "model_%d" % global_step) if not os.path.exists(save_path): os.makedirs(save_path) save_param_path = os.path.join(save_path, 'model_state.pdparams') paddle.save(model.state_dict(), save_param_path) tokenizer.save_pretrained(save_path) # 保存最后一个batch的模型 save_path = os.path.join(save_dir, "model_%d" % global_step) if not os.path.exists(save_path): os.makedirs(save_path) save_param_path = os.path.join(save_path, 'model_state.pdparams') paddle.save(model.state_dict(), save_param_path) tokenizer.save_pretrained(save_path)
#模型训练
do_train(model,train_data_loader,save_dir=save_dir)
8. 效果评估
评估过程首先加载召回集corpus.csv,然后抽取向量,插入到hnswlib索引引擎中,然后用测试集的每个query去hnswlib检索,得到返回结果后计算Recall@N。from data import gen_id2corpus
corpus_file = ‘baoxian/corpus.csv’
id2corpus = gen_id2corpus(corpus_file)
#conver_example function’s input must be dict
corpus_list = [{idx: text} for idx, text in id2corpus.items()]
print(corpus_list[:4])from data import convert_example_test
trans_func_corpus = partial(
convert_example_test,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
batchify_fn_corpus = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # text_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # text_segment
): [data for data in fn(samples)]
corpus_ds = MapDataset(corpus_list)
corpus_data_loader = create_dataloader(
corpus_ds,
mode=‘predict’,
batch_size=batch_size,
batchify_fn=batchify_fn_corpus,
trans_fn=trans_func_corpus)
for item in corpus_data_loader:
print(item)
break上图显示的是预测数据的id的形式,第一个Tensor表示的是input_ids,第二个Tensor表示的是Token_type_ids。使用hnswlib来构建索引库。

支持三种距离计算的方式,本项目使用的是ip,内积的方式
更多参数设置信息可以参考链接:https://github.com/nmslib/hnswlib。from ann_util import build_index
#索引的大小
hnsw_max_elements=1000000
#控制时间和精度的平衡参数
hnsw_ef=100
hnsw_m=100
final_index = build_index(corpus_data_loader, model,output_emb_size=output_emb_size,hnsw_max_elements=hnsw_max_elements,
hnsw_ef=hnsw_ef,
hnsw_m=hnsw_m)def gen_text_file(similar_text_pair_file):
text2similar_text = {}
texts = []
with open(similar_text_pair_file, ‘r’, encoding=‘utf-8’) as f:
for line in f:
splited_line = line.rstrip().split("\t")
if len(splited_line) != 2:
continue
text, similar_text = line.rstrip().split("\t")
if not text or not similar_text:
continue
text2similar_text[text] = similar_text
texts.append({"text": text})
return texts, text2similar_textsimilar_text_pair_file=‘baoxian/test_pair.csv’
text_list, text2similar_text = gen_text_file(similar_text_pair_file)
print(text_list[:2])
#print(text2similar_text)query_ds = MapDataset(text_list)
query_data_loader = create_dataloader(
query_ds,
mode=‘predict’,
batch_size=batch_size,
batchify_fn=batchify_fn_corpus,
trans_fn=trans_func_corpus)
query_embedding = model.get_semantic_embedding(query_data_loader)
recall_result_dir=‘recall_result_dir’
os.makedirs(recall_result_dir,exist_ok=True)recall_num = 10
recall_result_file = ‘recall_result.txt’
recall_result_file = os.path.join(recall_result_dir,
recall_result_file)
with open(recall_result_file, ‘w’, encoding=‘utf-8’) as f:
for batch_index, batch_query_embedding in enumerate(query_embedding):
recalled_idx, cosine_sims = final_index.knn_query(
batch_query_embedding.numpy(), recall_num)
batch_size = len(cosine_sims)
for row_index in range(batch_size):
text_index = batch_size * batch_index + row_index
for idx, doc_idx in enumerate(recalled_idx[row_index]):
f.write("{}\t{}\t{}\n".format(text_list[text_index][
“text”], id2corpus[doc_idx], 1.0 - cosine_sims[
row_index][idx]))recall_N = []
from evaluate import recall
from data import get_rs
similar_text_pair=“baoxian/test_pair.csv”
rs=get_rs(similar_text_pair,recall_result_file,10)
recall_num = [1, 5, 10]
for topN in recall_num:
R = round(100 * recall(rs, N=topN), 3)
recall_N.append(str®)
for key, val in zip(recall_num, recall_N):
print(‘recall@{}={}’.format(key, val))
9. 模型推理
取出一条文本数据,模型预测得到向量后,利用hnswlib进行向量检索,得到候选的问题。example=“买了社保,是不是就不用买商业保险了?”
print(‘输入文本:{}’.format(example))
encoded_inputs = tokenizer(
text=[example],
max_seq_len=max_seq_length)
input_ids = encoded_inputs[“input_ids”]
token_type_ids = encoded_inputs[“token_type_ids”]
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
cls_embedding=model.get_pooled_embedding( input_ids=input_ids,token_type_ids=token_type_ids)
#print(‘提取特征:{}’.format(cls_embedding))
recalled_idx, cosine_sims = final_index.knn_query(
cls_embedding.numpy(), 10)
print(‘检索召回’)
for doc_idx,cosine_sim in zip(recalled_idx[0],cosine_sims[0]):
print(id2corpus[doc_idx],cosine_sim)
输入的文本是:“买了社保,是不是就不用买商业保险了?”,经过向量检索,返回了10个候选的问题,其中第一个问题跟输入文本非常接近,说明得到了正确的召回。
下一步就把召回的第一条数据的答案返回给用户:
社保是基础的,就是我们通常说的“五险”包括:基本养老保险、基本医疗保险、失业保险、工伤保险和生育保险。而商业保险则是保障。
10 预测部署
预测部署首先需要把动态图模型转换成静态图,然后基于Mivus构建近似向量检索引擎,向Mivus的索引库中插入语料的向量,最后把抽取向量用PaddleServing部署,使得线上的文本都能够从paddleServing抽取向量。
下面为大家展示部署的几个关键步骤:
10.1 动转静导出
首先把模型转换成静态图模型。output_path=‘output’
#切换成eval模式,关闭dropout
model.eval()
#Convert to static graph with specific input description
model = paddle.jit.to_static(
model,
input_spec=[
paddle.static.InputSpec(
shape=[None, None], dtype=“int64”), # input_ids
paddle.static.InputSpec(
shape=[None, None], dtype=“int64”) # segment_ids
])
#Save in static graph model.
save_path = os.path.join(output_path, “inference”)
paddle.jit.save(model, save_path)
10.2 问答检索引擎
模型准备结束以后,开始搭建 Milvus 的语义检索引擎,用于语义向量的快速检索,本项目使用Milvus开源工具进行向量检索,Milvus 的搭建教程请参考官方教程 Milvus官方安装教程本案例使用的是 Milvus 的1.1.1 CPU版本,建议使用官方的 Docker 安装方式,简单快捷。
10.3 Paddle Serving 部署
使用Pipeline的方式进行部署。dirname=“output”
#模型的路径
model_filename=“inference.get_pooled_embedding.pdmodel”
#参数的路径
params_filename=“inference.get_pooled_embedding.pdiparams”
#server的保存地址
server_path=“serving_server”
#client的保存地址
client_path=“serving_client”
#指定输出的别名
feed_alias_names=None
#制定输入的别名
fetch_alias_names=“output_embedding”
#设置为True会显示日志
show_proto=False
serving_io.inference_model_to_serving(
dirname=dirname,
serving_server=server_path,
serving_client=client_path,
model_filename=model_filename,
params_filename=params_filename,
show_proto=show_proto,
feed_alias_names=feed_alias_names,
fetch_alias_names=fetch_alias_names)搭建结束以后,就可以启动server部署服务,使用client端访问server端就行了。具体细节参考代码:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/question_answering/faq_finance/deploy/python!rm -rf output/
#!rm -rf checkpoints/
!rm -rf serving_server/
!rm -rf serving_client/
11 参考文献
[1] Gao, Tianyu, Xingcheng Yao, and Danqi Chen. “SimCSE: Simple Contrastive Learning of Sentence Embeddings.” ArXiv:2104.08821 [Cs], April 18, 2021. http://arxiv.org/abs/2104.08821.
[2] Wu, Xing, et al. “ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding.” arXiv preprint arXiv:2109.04380 (2021). https://arxiv.org/abs/2109.04380.
[3] Liang, Xiaobo, Lijun Wu, Juntao Li, Yue Wang, Qi Meng, Tao Qin, Wei Chen, Min Zhang, and Tie-Yan Liu. “R-Drop: Regularized Dropout for Neural Networks.” ArXiv:2106.14448 [Cs], June 28, 2021. http://arxiv.org/abs/2106.14448.


 微信联系
微信联系
