当前,诸多投资机构都通过研报的形式给出对于股票、基金以及行业的判断,让大众了解热点方向、龙头公司等各类信息。然而,分析和学习研报往往花费大量时间,研报数目的与日俱增也使得自动对研报分析和信息抽取的诉求不断提高。
本案例以文档场景下的文字识别和命名实体识别为串联任务,对研报实体进行词频统计,使用PaddleOCR和PaddleNLP两个开发套件,迅速搭建一套文字与命名实体识别统计系统。
如果您拥研报数据并希望进一步训练,可以上传数据后依次按照说明执行;如果仅有少量的研报数据,可以使用本项目中经过微调的检测模型,在完成环境配置后直接跳转到2.3节,对图片研报数据进行OCR可视化
1. 环境配置
运行下方代码,安装PaddleOCR的依赖库、PaddleNLP whl包以及pdf转换工具%cd ~/PaddleOCR
#安装依赖库
!pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
#安装PaddleNLP whl包
!pip install --upgrade paddlenlp
#安装pdf转图片包
!pip install fitz PyMuPDF
2. 文档场景文本检测模型微调
2.1 数据与预训练模型准备
2.1.1 数据解压与移动
获取研报的渠道有很多,比如各种研究机构以及各类国家机构的公开数据,大家可以自行下载。下方仅提供流程上的实例代码,不具有实际意义# 数据解压与移动
!mkdir ~/PaddleOCR/train_data/ # 新建数据文件夹
%cd ~/data/data # 移动至数据文件夹
!unzip -oq Research_val.zip && mv Research_val ~/PaddleOCR/train_data/ # 解压文件夹下的验证数据
!unzip -oq Research_train.zip && mv Research_train ~/PaddleOCR/train_data/ # 解压文件夹下的训练数据
%cd ~/PaddleOCR
2.1.2 预训练模型下载
当数据按照PP-OCR格式整理好后,开始训练前首先需要下载预训练模型。在PP-OCR模型库下载PP-OCR mobile系列的检测模型到./pretrain_models文件夹中并解压
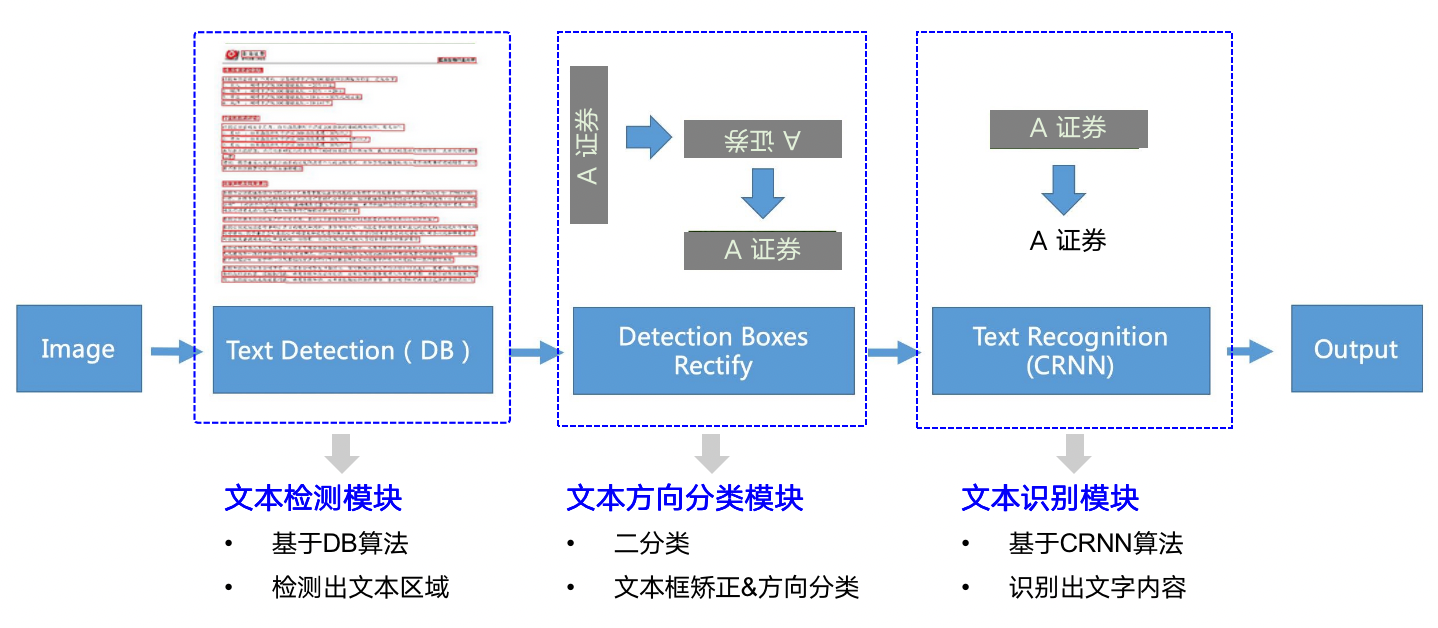
PP-OCR是一个实用的超轻量OCR系统。主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身。更多细节请参考PP-OCR技术方案
#PP-OCR mobile检测模型下载与解压
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar
!cd pretrain_models/ && tar xf ch_ppocr_mobile_v2.0_det_train.tar得到的文件目录结构如下
./pretrain_models/ch_ppocr_mobile_v2.0_det_train/ └─ best_accuracy.pdopt └─ best_accuracy.pdparams └─ best_accuracy.states
其他模型下载方式相同,也可通过PaddleOCR github下载更多模型# PP-OCR v2检测模型下载与解压
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
!cd pretrain_models/ && tar xf ch_PP-OCRv2_det_distill_train.tar
2.2 模型训练与评估
2.2.1 修改配置文件
配置文件是模型训练过程中必不可少的部分,它是由模型参数和训练过程参数组成的集合。对./configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml配置文件的修改包括预训练模型路径、数据集路径两部分。通过Global.pretrained_model指定配置文件中的预训练模型路径。修改配置文件中的data_dir, label_file_list为数据所在路径。(本项目中配置文件已修改)
Global: └─pretrained_model:./pretrain_models/ch_ppocr_mobile_v2.0_det_train/best_accuracy Train: └─dataset └─data_dir:./train_data └─label_file_list:./train_data/Research_train/label.txt # path/to/your/dataset/label.txt eval: └─dataset └─data_dir:./train_data └─label_file_list:./train_data/Research_val/label.txt # path/to/your/dataset/label.txt
注意:
训练程序在读取数据时,读取的文件路径为
data_dir路径 + label.txt中的文件名,需要注意组合后的路径与图片路径相同。配置文件修改可通过上述方式直接更改yml,也可通过在下方启动训练命令中指定
-o Global.pretrained_model实现
2.2.2 启动训练
训练平台使用AI Studio,通过-c选择与模型相同的配置文件ch_det_mv3_db_v2.0.yml# 单机单卡训练 PP-OCR mobile 模型
!python3 tools/train.py -c ./configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml
训练其他模型可以运行一下代码,同时按照上述配置文件的修改方法修改# 单机单卡训练 PP-OCR v2 模型
!python3 tools/train.py -c ./configs/det/ch_PP-OCRv2/ch_PP-OCR_det_cml.yml# 单机单卡训练 mv3_db 模型
!python3 tools/train.py -c configs/det/det_mv3_db.yml
-o Global.pretrain_weights=./pretrain_models/MobileNetV3_large_x0_5_pretrained
2.2.3 断点训练
当程序中值后,重新启动训练可通过Global.checkpoints读入之前训练的权重./output/db_mv3/latest!python3
tools/train.py -c configs/det/det_mv3_db.yml -o
Global.checkpoints=./output/db_mv3/latest!python3 tools/train.py -c
configs/det/ch_PP-OCRv2/ch_PP-OCR_det_cml.yml -o
Global.checkpoints=./output/PP_ch_db_mv3/latest注意:Global.checkpoints的优先级高于Global.pretrained_model的优先级,即同时指定两个参数时,优先加载Global.checkpoints指定的模型,如果Global.checkpoints指定的模型路径有误,会加载Global.pretrained_model指定的模型。
2.2.4 测试集评估
PaddleOCR计算三个OCR检测相关的指标,分别是:Precision、Recall、H-mean(F-Score)。
训练中模型参数默认保存在Global.save_model_dir目录下。在评估指标时,需要设置Global.checkpoints指向保存的参数文件。# 原始模型
!python3 tools/eval.py -c
configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
Global.checkpoints="./pretrain_models/ch_ppocr_mobile_v2.0_det_train/best_accuracy"
#Finetune后模型
!python3 tools/eval.py -c
configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
Global.checkpoints="./output/ch_db_mv3/best_accuracy"获得结果如下,经过finetune后的模型在综合指标H-mean上比原先提升3%左右。
| Model | Precision | Recall | H-mean |
|---|---|---|---|
| PP-OCR mobile | 0.770 | 0.890 | 0.826 |
| PP-OCR mobile finetune | 0.833 | 0.882 | 0.856 |
2.3 结果可视化
首先将训练模型转换为inference模型,加载配置文件ch_det_mv3_db_v2.0.yml,从output/ch_db_mv3目录下加载best_accuracy模型,inference模型保存在./output/ch_db_mv3_inference目录下!python3
tools/export_model.py -c
configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
Global.pretrained_model="./output/ch_db_mv3/best_accuracy"
Global.save_inference_dir="./output/ch_db_mv3_inference/"然后在实例化PaddleOCR时通过参数det_model_dir指定转化后的模型位置; 通过img_path指定一张待测图片, 最终可视化结果保存在result.jpg中
如果您的数据还是pdf格式,可以先参考4.1节完成数据切分from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(det_model_dir=’./output/ch_db_mv3_inference/inference’,
use_angle_cls=True)
img_path = ‘./doc/imgs_en/img_12.jpg’ # 替换此处的图片路径为您的图片
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
#显示结果
from PIL import Image
image = Image.open(img_path).convert(‘RGB’)
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path=’./doc/fonts/simfang.ttf’)
im_show = Image.fromarray(im_show)
im_show.save(‘result.jpg’)
3. 命名实体识别
什么是实体?实体,可以认为是某一个概念的实例,
命名实体识别(Named Entities Recognition,NER),就是识别这些实体指称的边界和类别。主要关注人名、地名和组织机构名这三类专有名词的识别方法。
词法分析任务即可获得句子中的实体。该任务的输入是一个字符串(句子),输出是句子中的词边界和词性、实体类别。其中能够识别的标签和对应含义如下表所示:
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | t | 时间 |
| nr | 人名 | ns | 地名 | nt | 机构名 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
用户可以使用PaddleNLP提供的Taskflow工具来对输入的文本进行一键分词,具体使用方法如下。对于其中的机构名,可以根据标签 ORG、 nt 抽出。from paddlenlp import Taskflow
tag = Taskflow(“pos_tagging”)
tag(“第十四届全运会在西安举办”)
#>>>[(‘第十四届’, ‘m’), (‘全运会’, ‘nz’), (‘在’, ‘p’), (‘西安’, ‘LOC’), (‘举办’, ‘v’)]
tag([“第十四届全运会在西安举办”, “三亚是一个美丽的城市”])
#>>> [[(‘第十四届’, ‘m’), (‘全运会’, ‘nz’), (‘在’, ‘p’), (‘西安’, ‘LOC’),
(‘举办’, ‘v’)], [(‘三亚’, ‘LOC’), (‘是’, ‘v’), (‘一个’, ‘m’), (‘美丽’, ‘a’),
(‘的’, ‘u’), (‘城市’, ‘n’)]]
关于词法分析的详细说明文档可以参考 此处 ,其中包含在自定义数据集上的训练、评估和导出。
4. Pipeline
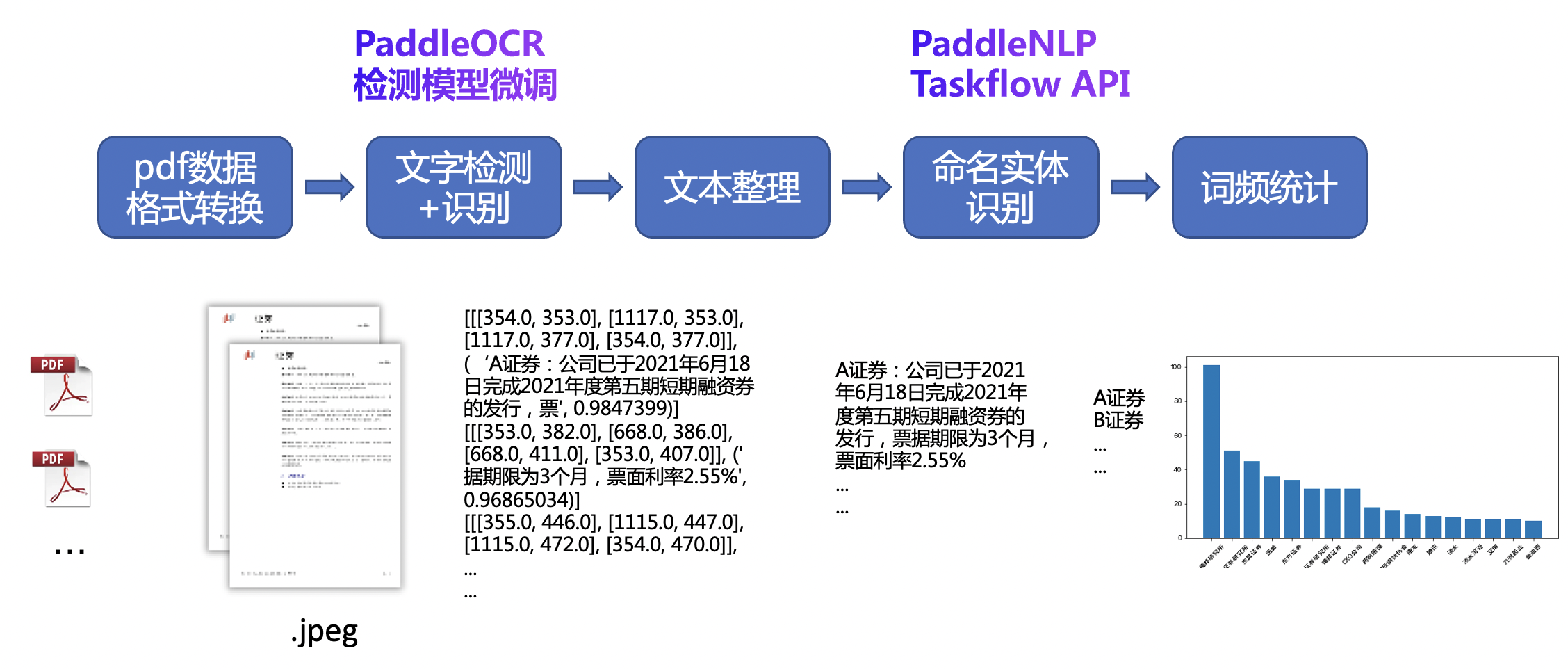
整个系统包含一下流程:首先对pdf格式的研报拆分为图片格式,然后对每张图片进行ocr,得到结果后输入LAC分词工具提取其中出现的机构名,最后统计同一个pdf研报下机构名出现的频率,得到当前研报主要关注的机构。批量统计多个研报后即可得到当前主要研究的热点领域和机构等
4.1 数据切分
运行下方代码,将需要分析的pdf数据放置在 ./ResearchReport 下,即可将pdf拆分成图片,每个pdf保存为一个文件夹# pdf切分
import os, fitz, time
def pdf2png(pdfPath, imgPath, zoom_x=2, zoom_y=2, rotation_angle=0):
‘’’
# 将PDF转化为图片
pdfPath pdf文件的路径
imgPath 图像要保存的文件夹
zoom_x x方向的缩放系数
zoom_y y方向的缩放系数
rotation_angle 旋转角度
‘’’
time_start = time.time()
# 打开PDF文件
pdf = fitz.open(pdfPath)
# 逐页读取PDF
for pg in range(0, pdf.pageCount):
page = pdf[pg]
# 设置缩放和旋转系数
trans = fitz.Matrix(zoom_x, zoom_y)
pm = page.getPixmap(matrix=trans, alpha=False)
if pm.width>2000 or pm.height>2000:
pm = page.getPixmap(matrix=fitz.Matrix(1, 1), alpha=False)
pm.writePNG(imgPath + str(pg) + ".jpeg")
pdf.close()
time_end = time.time()
time_cost = time_end - time_start
print('totally cost: {}, page: {}, each page cost: {}'.format(time_cost, pg+1, time_cost/(pg+1)))if name == ‘main’:
pdfFolder = ‘ResearchReport’
for p in os.listdir(pdfFolder):
if p[-4:] == ‘.pdf’:
pdfPath = pdfFolder+’/’+p
imgPath = pdfFolder+’/’+os.path.basename§[:-4]+’/’
print(imgPath)
os.mkdir(imgPath)
pdf2png(pdfPath, imgPath)如果您使用CPU版本的AI Stuidio,请将下方的 PaddleOCR(det_model_dir='./PaddleOCR/output/ch_db_mv3_inference/inference',use_angle_cls=True) 添加 use_gpu = False
4.2 获得词频统计结果
运行下方代码,程序将读取./ResearchReport下的图片文件夹,在PaddleOCR中使用前述训练的检测推理模型'./PaddleOCR/output/ch_db_mv3_inference/inference'完成OCR检测,利用paddlenlp中的TaskflowAPI进行分词任务,然后根据标签nt,ORG筛选出组织机构名称。最终将词频统计图保存在'./img.png'中。
注意,原始代码只展示出出现频率大于10次的机构名称,如需更改请自行调整# ocr识别
from paddleocr import PaddleOCR, draw_ocr
from paddlenlp import Taskflow
from collections import Counter
import matplotlib.pyplot as plt
import matplotlib
#命名实体识别与词频统计
def deletaNum(doc):
return [i for i in doc if len(i)>1]
def LAC(lac, res_list): # 根据结果筛选
doc = [text[1][0] for res in res_list for text in res]
doc = deletaNum(doc)
# print('\n\ndoc is ',doc)
lac_dic = lac(doc)
enti = []
for la in lac_dic:
ent = []
for l in la:
if l[1] in ['nt','ORG']:
ent.append(l[0])
enti += ent
return entidef PlotHist(counter):
matplotlib.rc(“font”,family=‘FZHuaLi-M14S’)
cnt = {}
for key in counter.keys():
if counter[key]>=10: # 此处只绘制出现频率大于10的机构
cnt[key] = counter[key]
print(cnt)
plt.figure(figsize=(10,5))
plt.bar(range(len(cnt)), cnt.values(), tick_label = list(cnt.keys()))
plt.xticks(rotation=45)
plt.savefig('./img.png')
plt.show()if name == ‘main’:
# 模型路径下必须含有model和params文件
ocr = PaddleOCR(det_model_dir=’./PaddleOCR/output/ch_db_mv3_inference/inference’,
use_angle_cls=True)
lac = Taskflow(“pos_tagging”)
enti_list = []
pdfFolder = './ResearchReport'
for p in os.listdir(pdfFolder):
if os.path.isdir(os.path.join(pdfFolder,p)):
print('Processing folder:', p)
imgPath = pdfFolder+'/'+p
res_list = []
for i in os.listdir(imgPath):
img_path = os.path.join(imgPath,i)
result = ocr.ocr(img_path, cls=True)
res_list.append(result)
enti = LAC(lac, res_list)
enti_list += enti
counter = Counter(enti_list)
print('Entity results:', counter)
PlotHist(counter)请点击此处查看本环境基本用法.
Please click here for more detailed instructions.


 微信联系
微信联系
