信息抽取定义以及难点
自动从无结构或半结构的文本中抽取出结构化信息的任务, 主要包含的任务包含了实体识别、关系抽取、事件抽取、情感分析、评论抽取等任务; 同时信息抽取涉及的领域非常广泛,信息抽取的技术需求高,下面具体展现一些示例


需求跨领域跨任务:领域之间知识迁移难度高,如通用领域知识很难迁移到垂类领域,垂类领域之间的知识很难相互迁移;存在实体、关系、事件等不同的信息抽取任务需求。
定制化程度高:针对实体、关系、事件等不同的信息抽取任务,需要开发不同的模型,开发成本和机器资源消耗都很大。
训练数据无或很少:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高。
针对以上难题,中科院软件所和百度共同提出了一个大一统诸多任务的通用信息抽取技术 UIE(Unified Structure Generation for Universal Information Extraction),发表在ACL‘22。UIE在实体、关系、事件和情感等4个信息抽取任务、13个数据集的全监督、低资源和少样本设置下,UIE均取得了SOTA性能。
PaddleNLP结合文心大模型中的知识增强NLP大模型ERNIE 3.0,发挥了UIE在中文任务上的强大潜力,开源了首个面向通用信息抽取的产业级技术方案,不需要标注数据(或仅需少量标注数据),即可快速完成各类信息抽取任务。
喜欢这个功能的朋友,欢迎点个⭐️star⭐支持我们(链接指路:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie )一起进步❤️❤️

也欢迎加入PaddleNLP的技术交流群(微信),一起交流NLP技术!入群有PaddleNLP官方直播课链接,以及10G重磅NLP学习大礼包哦!

直播课内容:
✅ ACL’22 顶会Paper,产业级通用信息抽取技术UIE
✅ ERNIE 3.0轻量级模型讲解
NLP学习礼包:
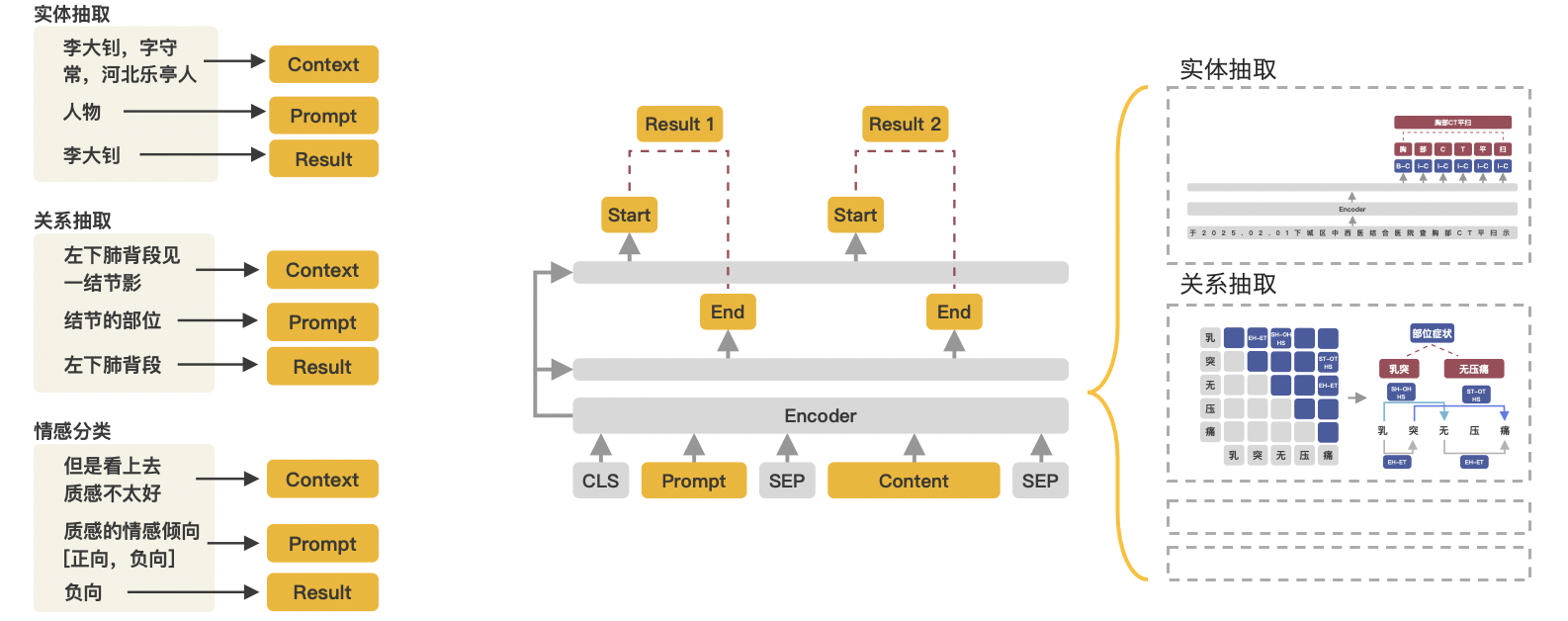
如何使用PaddleNLP Taskflow工具解决信息抽取难点
安装PaddleNLP
! pip install --upgrade paddlenlp
! pip show paddlenlp
使用Taskflow UIE任务看看效果
人力资源入职证明信息抽取
from paddlenlp import Taskflow
schema = [‘名称’, ‘毕业院校’, ‘职位’, ‘月收入’, ‘身体状况’]
ie = Taskflow(‘information_extraction’,
schema=schema)ie(‘兹证明凌霄为本单位职工,已连续在我单位工作5 年。学历为嘉利顿大学毕业,目前在我单位担任总经理助理
职位。近一年内该员工在我单位平均月收入(税后)为 12000 元。该职工身体状况良好。本单位仅此承诺上述表述是正确的,真实的。’)#
Jupyter Notebook默认做了格式化输出,如果使用其他代码编辑器,可以使用Python原生包pprint进行格式化输出
from pprint import pprint
pprint(ie(‘兹证明凌霄为本单位职工,已连续在我单位工作5 年。学历为嘉利顿大学毕业,目前在我单位担任总经理助理
职位。近一年内该员工在我单位平均月收入(税后)为 12000 元。该职工身体状况良好。本单位仅此承诺上述表述是正确的,真实的。’))
医疗病理分析schema = [‘肿瘤部位’, ‘肿瘤大小’]
ie.set_schema(schema)
ie(‘胃印戒细胞癌,肿瘤主要位于胃窦体部,大小6*2cm,癌组织侵及胃壁浆膜层,并侵犯血管和神经。’)
使用Taskflow UIE进行实体抽取、关系抽取、事件抽取、情感分析、观点抽取# 实体抽取
schema = [‘时间’, ‘赛手’, ‘赛事名称’]
ie.set_schema(schema)
ie(‘2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!’)# 关系抽取
schema = {‘歌曲名称’: [‘歌手’, ‘所属专辑’]}
ie.set_schema(schema)
ie(’《告别了》是孙耀威在专辑爱的故事里面的歌曲’)# 事件抽取
schema = {‘地震触发词’: [‘地震强度’, ‘时间’, ‘震中位置’, ‘震源深度’]} # 事件需要通过xxx触发词来选择触发词
ie.set_schema(schema)
ie(‘中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。’)# 情感倾向分类
schema = ‘情感倾向[正向,负向]’ # 分类任务需要[]来设置分类的label
ie.set_schema(schema)
ie(‘这个产品用起来真的很流畅,我非常喜欢’)# 评价抽取
schema = {‘评价维度’: ‘观点词’} # 评价抽取的schema是固定的,后续直接按照这个schema进行观点抽取
ie.set_schema(schema) # Reset schema
ie(‘个人觉得管理太混乱了,票价太高了’)# 跨任务跨领域抽取
schema = [‘寺庙’, {‘丈夫’: ‘妻子’}] # 抽取的任务中包含了实体抽取和关系抽取
ie.set_schema(schema)
ie(‘李治即位后,让身在感业寺的武则天续起头发,重新纳入后宫。’)
使用Taskflow UIE一些技巧
1. schema设置可以多尝试,有惊喜!schema = [‘才人’]
ie.set_schema(schema)
ie(‘李治即位后,让身在感业寺的武则天续起头发,重新纳入后宫。’)schema = [‘妃子’]
ie.set_schema(schema)
ie(‘李治即位后,让身在感业寺的武则天续起头发,重新纳入后宫。’)
2. 调整batch_size和使用小模型来提升预测效率from paddlenlp import Taskflow
schema = [‘费用’]
ie = Taskflow(‘information_extraction’, schema=schema, batch_size=2)
ie([‘二十号21点49分打车回家46块钱’, ‘8月3号往返机场交通费110元’, ‘2019年10月17日22点18分回家打车46元’, ‘三月三0号23点10分加班打车21元’])
小样本提升UIE效果
Taskflow中的UIE基线版本我们是通过大量的有标签样本进行训练,但是UIE抽取的效果面对部分子领域的效果也不是令人满意,UIE可以通过小样本就可以快速提升效果。
为什么UIE可以通过小样本来提升效果呢?UIE的建模方式主要是通过 prompt 方式来建模, prompt 在小样本上进行微调效果非常有效,下面我们通过一个具体的case
来展示UIE微调的效果。
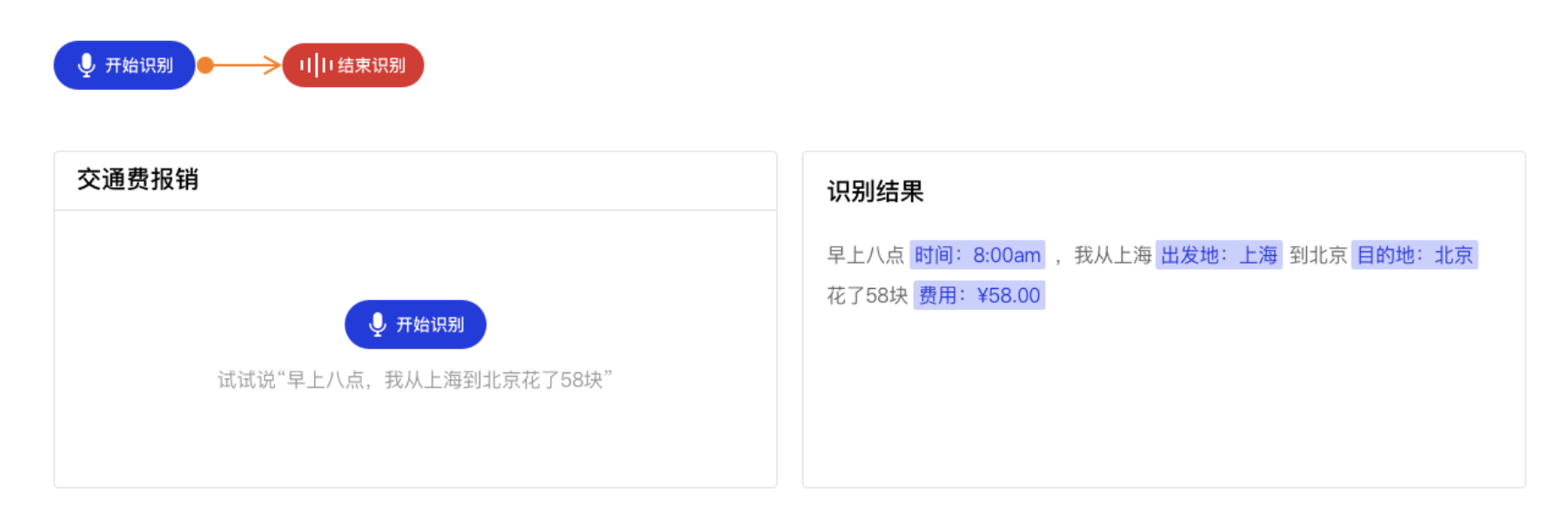
语音报销工单信息抽取
1. 背景
在某公司内部可以通过语音输入来报销打车费用,通过语音ASR模型可以将语音识别为文字,同时对文字信息进行信息抽取,抽取的信息主要是包括了4个方面,时间、出发地、目的地、费用,通过对文字4个方面的信息进行抽取就可以完成一个报销工单的填写。
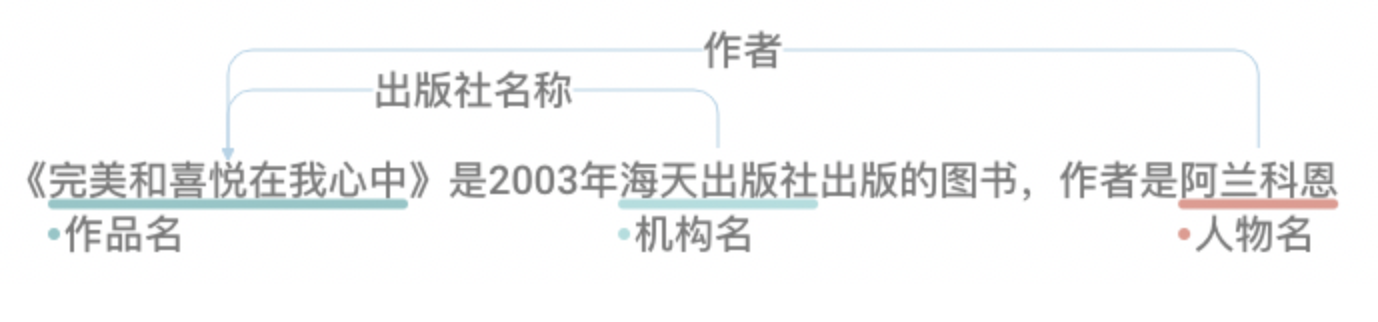
2. 挑战
目前Taskflow UIE任务对于这种非常垂类的任务效果没有完全达到工业使用水平,因此需要一定的微调手段来完成UIE模型的微调来提升模型的效果,下面是一些case的展现
ie.set_schema([‘时间’, ‘出发地’, ‘目的地’, ‘费用’])
ie(‘10月16日高铁从杭州到上海南站车次d5414共48元’) # 无法准确抽取出发地、目的地
标注数据
我们推荐使用数据标注平台doccano
进行数据标注,本案例也打通了从标注到训练的通道,即doccano导出数据后可通过doccano.py脚本轻松将数据转换为输入模型时需要的形式,实现无缝衔接。为达到这个目的,您需要按以下标注规则在doccano平台上标注数据:
Step 1. 本地安装doccano(请勿在AI Studio内部运行,本地测试环境python=3.8)
$ pip install doccano
Step 2. 初始化数据库和账户(用户名和密码可替换为自定义值)
$ doccano init
$ doccano createuser --username my_admin_name --password my_password
Step 3. 启动doccano
在一个窗口启动doccano的WebServer,保持窗口
$ doccano webserver --port 8000
在另一个窗口启动doccano的任务队列
$ doccano task
Step 4. 运行doccano来标注实体和关系
打开浏览器(推荐Chrome),在地址栏中输入
http://0.0.0.0:8000/后回车即得以下界面。登陆账户。点击右上角的
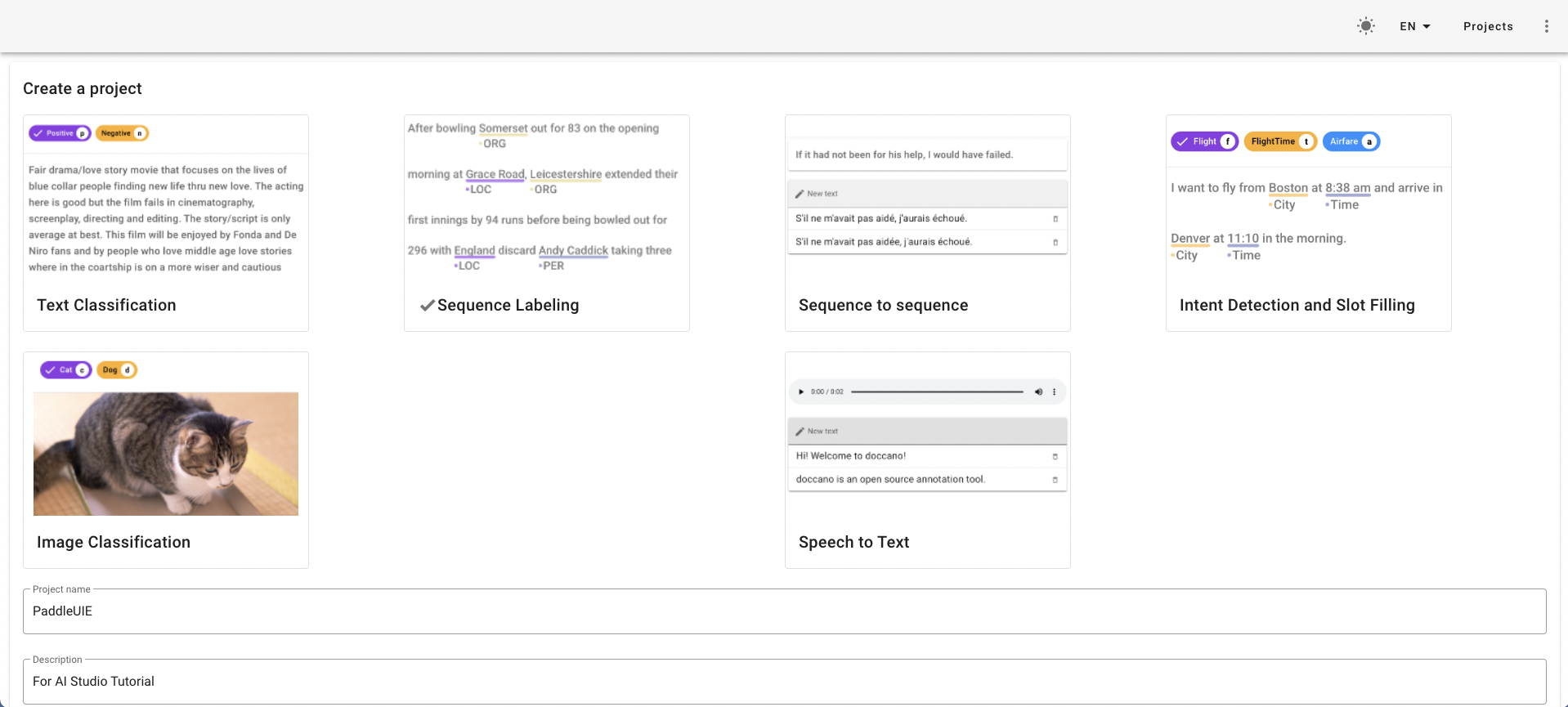
LOGIN,输入Step 2中设置的用户名和密码登陆。创建项目。点击左上角的
CREATE,跳转至以下界面。勾选序列标注(
Sequence Labeling)填写项目名称(
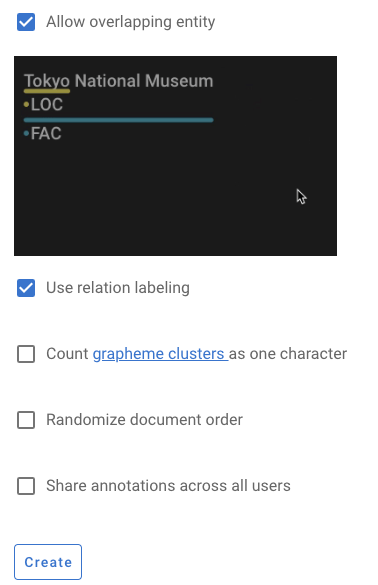
Project name)等必要信息勾选允许实体重叠(
Allow overlapping entity)、使用关系标注(Use relation labeling)创建完成后,项目首页视频提供了从数据导入到导出的七个步骤的详细说明。
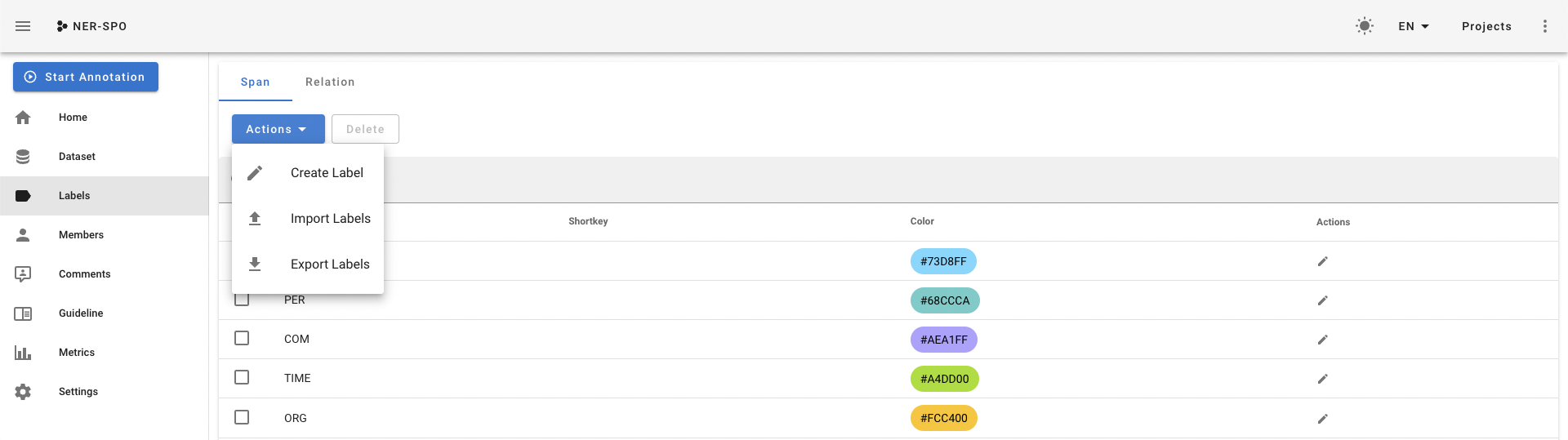
设置标签。在Labels一栏点击
Actions,Create Label手动设置或者import Labels从文件导入。最上边Span表示实体标签,Relation表示关系标签,需要分别设置。
导入数据。在Datasets一栏点击
Actions、import Dataset从文件导入文本数据。根据文件格式(File format)给出的示例,选择适合的格式导入自定义数据文件。
导入成功后即跳转至数据列表。
标注数据。点击每条数据最右边的
Annotate按钮开始标记。标记页面右侧的标签类型(Label Types)开关可在实体标签和关系标签之间切换。实体标注:直接用鼠标选取文本即可标注实体。
关系标注:首先点击待标注的关系标签,接着依次点击相应的头尾实体可完成关系标注。
导出数据。在Datasets一栏点击
Actions、Export Dataset导出已标注的数据。
将标注数据转化成UIE训练所需数据
将doccano平台的标注数据保存在
./data/目录。对于语音报销工单信息抽取的场景,可以直接下载标注好的数据。
各个任务标注文档
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/doccano.md!
wget
https://paddlenlp.bj.bcebos.com/datasets/erniekit/speech-cmd-analysis/audio-expense-account.jsonl
! mv audio-expense-account.jsonl ./data/- 运行以下代码将标注数据转换为UIE训练所需要的数据!
python preprocess.py --input_file ./data/audio-expense-account.jsonl
--save_dir ./data/ --negative_ratio 5 --splits 0.2 0.8 0.0 --seed 1000
训练UIE模型
使用标注数据进行小样本训练,模型参数保存在
./checkpoint/目录。! python finetune.py --train_path ./data/train.txt --dev_path ./data/dev.txt --save_dir ./checkpoint --model uie-base --learning_rate 1e-5 --batch_size 16 --max_seq_len 512 --num_epochs 50 --seed 1000 --logging_steps 10 --valid_steps 10- 使用小样本训练后的模型参数再次测试无法正确抽取的case。from paddlenlp import Taskflow
schema = [‘时间’, ‘出发地’, ‘目的地’, ‘费用’]
few_ie = Taskflow(‘information_extraction’, schema=schema, task_path=’./checkpoint/model_best’)
few_ie([‘10月16日高铁从杭州到上海南站车次d5414共48元’,
‘6月7日苏州街地铁站到海淀黄庄’,
‘10月22日从公司到首都机场38元过路费’])## 结束语
相信大家已经掌握了如何使用UIE技术完成信息抽取任务,快快动手体验吧!
如有疑问,可加入PaddleNLP的技术交流群(微信),一起交流NLP技术!入群有PaddleNLP官方直播课链接,以及10G重磅NLP学习大礼包哦!
本项目基于PaddleNLP。
如果对您有帮助,欢迎star收藏一下,不易走丢哦~链接指路:https://github.com/PaddlePaddle/PaddleNLP


 微信联系
微信联系
