1. 项目说明
本示例是基于 PaddlSeg 2.1 版本实现的 U-HRNet,并提供了基于 ImageNet 数据集的 W18-small 和 W48 版本的预训练模型,并在 Cityscapes 数据集进行了训练。


图 1 - 车辆检测模型效果
方案难点: 在地面要素分割、人像分割、医学图像分割等对分割精度要求比较高的分割场景下,往往存在一些细长或者较小的待分割元素,由于这些元素前景占比较非常小,因此想要达到比较高的分割精度,就要探索如何在维持高分辨率特征的前提下,近一��增强低分辨率的语义信息,以及高低分辨率特征之间的信息交互。
应用场景:
地图要素分割
人像分割
医学图像分割
其他适合 U 型高分辨语义分割网络的应用场景
2. 安装说明
2.1 环境要求
PaddlePaddle 2.2.2
Python 3(3.5.1+/3.6/3.7/3.8/3.9)
CUDA >= 10.1
cuDNN >= 7.6
2.2 解压数据及代码
项目代码在 PaddleSeg.tar 文件中,数据集在 cityscapes.tar 文件中,解压到合适路径即可使用。# 如果希望解压到其他目录
#可选择其他路径(默认 /home/aistudio )
%cd ~
! unzip -qo ~/data/data141439/PaddleSeg.zip
! rm -rf __MACOSX
%cd ~/PaddleSeg
! mkdir data &&
tar xf ~/data/data141439/cityscapes.tar -C data
3. 数据准备
该项目提供 cityscapes 数据集,且上方代码已将其解压到 PaddleSeg 目录下,直接使用即可。
3.1 数据介绍
本案例使用的公开数据集 Cityscapes,共 5000 张精标注数据,其中训练集 2975 张,验证集 500 张,1525 张测试集。数据集展示如下图:

图 2 - 部分 Cityscapes 数据展示
3.2 数据结构
首先我们看一下文档树结构
cityscapes ├── gtFine │ ├── test │ ├── train │ └── val ├── infer.list ├── leftImg8bit │ ├── test │ ├── train │ └── val ├── test.list ├── train.list ├── trainval.list └── val.list
leftImg8bit 已经对 image 进行了划分,分为 train、val、test 文件夹。
train文件夹总共包含18个城市,为在全球选择的18个城市街景图片。
下图为 aachen 文件夹中包含的街景图片。命名规则是,第一部分设定是该文件夹的名字,第二部分是对应的第几张图片,第三/四部分固定是 000019 和 leftImg8bit.png。
图 3 - 随机选取的一张街景图片
gtFine 和 leftImg8bit 相同,分为三个文件夹,分别是 train、val、test。同样的,train 文件夹包含 18 个类,为相应的标签图片。
还是以 aachen 文件夹为例
aachen_000000_000019_gtFine_color.png 可视化的分割图 aachen_000000_000019_gtFine_instaceIds.png 实例分割标注文件 aachen_000000_000019_gtFine_labelIds.png 语义分割标注文件 aachen_000000_000019_gtFine_labelTrainIds.png 语义分割标注文件 aachen_000000_000019_gtFine_polygons.json 存储的是各个类和相应的区域 (用多边形顶点的位��表示区域的边界)
4. 模型选择
在 HRNet 中( HRNet 基于 PaddleSeg2.1 的训练和推理具体教程可参考 PaddleSeg全流程跑通 ),维持高分辨 feature map(1/4)的传播,有比较大的计算量,但是这部分语义信息相对较少,并且针对 1/32 低分辨率,具有更丰富语义信息的 feature map,没有更充分的利用。因此,我们基于这两点,通过
1)删减高分辨率 featue map 支路的计算量
2)增加对低分辨率语义信息的利用,以及高低分辨率信息的交互设计了 U 型高分辨率语义分割网络 UHRNet,并基于 PaddleSeg2.1 进行开发。
UHRNet 对于包含更多语义信息的低分辨率 feature map 进行更充分的利用,对于计算量非常大,但是包含语义信息相对较少的高分辨率 feature map 进行适当的简化,在保证计算量基本不变的情况,达到了更高的分割精度。
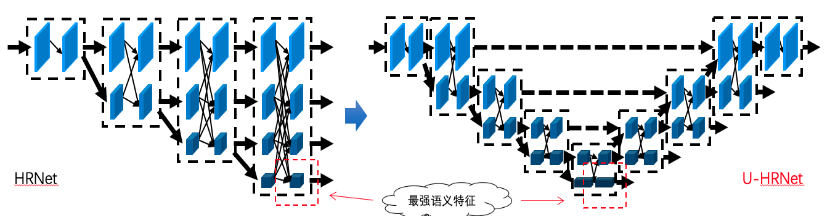
图 4 - 模型对比如图
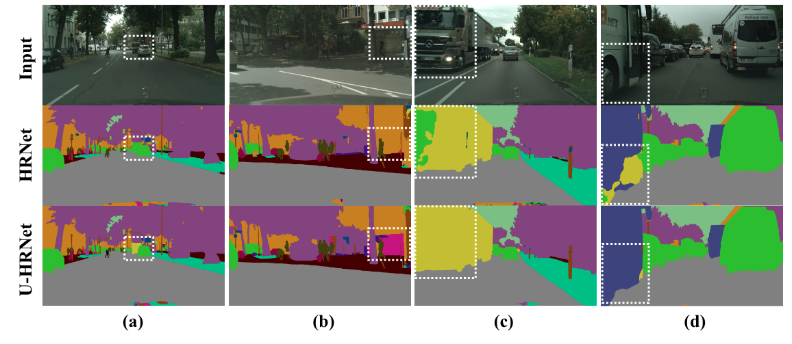
图 5 - UHRNet效果如图
模型优化效果对比:
| HRNet-W48 | U-HRNet-W48 | U-HRNet-W18-small | |
|---|---|---|---|
| mIoU | 0.8156 | 0.8206 | 0.7886 |
| Acc | - | 0.9677 | 0.9642 |
| Kappa | - | 0.9581 | 0.9536 |
如对模型性能有要求,可以采用 U-HRNet-W18-small。
5. 模型训练
训练被拆分成了针对 U-HRNet-W48 和 U-HRNet-W18-small 的两种方案。同时我们也提供了基于 ocr head 的训练配置,分数还会进一步上涨。
U-HRNet-W18-small: 模型位置: output_w18_4_gpus_120k/best_model mIoU: mIoU: 0.7886 Acc: 0.9642 Kappa: 0.9536 Class IoU: [0.9843 0.868 0.9312 0.6085 0.6496 0.6806 0.7141 0.7916 0.9295 0.6752 0.9516 0.8232 0.6275 0.9533 0.8042 0.8559 0.7366 0.6296 0.7693] Class Acc: [0.9931 0.9257 0.9613 0.8223 0.7997 0.8289 0.8296 0.9068 0.9595 0.8469 0.9713 0.8988 0.7623 0.9731 0.9276 0.9282 0.878 0.8117 0.8631] U-HRNet-W48: 模型位置: output_w48_4_gpus_120k/best_model mIoU: 0.8206 Acc: 0.9677 Kappa: 0.9581 Class IoU: [0.9855 0.8824 0.9373 0.6497 0.6827 0.7154 0.7584 0.8277 0.9317 0.6794 0.9545 0.8474 0.6691 0.9599 0.861 0.9099 0.8631 0.6784 0.7984] Class Acc: [0.993 0.9353 0.9669 0.8325 0.8434 0.8459 0.85 0.9186 0.9598 0.8376 0.9746 0.915 0.7899 0.9781 0.9423 0.9666 0.9425 0.8163 0.8813]
这里以 U-HRNet-W18-small 为例。首先,在启动模型训练之前,可以修改配置文件中相关内容, 包括显卡使用数量、预训练模型路径、模型输出路径。对应到配置文件中的位置如下所示:
U-HRNet-W18-small // 项目基础配置配置,包括数据增强、路径、优化器等信息 _base_: '../_base_/cityscapes.yml' batch_size: 3 iters: 120000 model: type: FCN backbone: type: UHRNet_W18_Small_V2 align_corners: False // 预训练模型 pretrained: pretrained_model/uhrnetw18_small_v2_imagenet/model.pdparams num_classes: 19 pretrained: Null backbone_indices: [-1] optimizer: weight_decay: 0.0005
项目中涉及多个配置文件信息,它们分别为
train.pyconfigs/fcn/fcn_uhrnetw18_small_v2_cityscapes_1024x512_120k.ymlconfigs/_base_/cityscapes.yml
还有一些其他的训练时配置诸如 save_interval、num_workers、log_iters 等,可以在 train.py 文件中调整。# U-HRNet-W18-small
! bash train_w18_4gpus.sh# U-HRNet-W48
! bash train_w48_4gpus.sh
6. 模型评估
评估默认配置:configs/fcn/fcn_uhrnetw48_cityscapes_1024x512_120k.yml。
具体配置可以到 yml 文件中查看,这里提供简单内容展���。
_base_: '../_base_/cityscapes.yml' // 批大小 batch_size: 3 // 迭代次数 iters: 120000 model: // 网络类型 type: FCN // 主干网络 backbone: type: UHRNet_W18_Small_V2 align_corners: False // 预训练模型 pretrained: pretrained_model/uhrnetw18_small_v2_imagenet/model.pdparams num_classes: 19 pretrained: Null backbone_indices: [-1] optimizer: weight_decay: 0.0005 ```! bash eval.sh评估结果如下: **W18-small 版本**
Images: 500 mIoU: 0.7886 Acc: 0.9642 Kappa: 0.9536
Class IoU:
[0.9843 0.868 0.9312 0.6085 0.6496 0.6806 0.7141 0.7916 0.9295 0.6752
0.9516 0.8232 0.6275 0.9533 0.8042 0.8559 0.7366 0.6296 0.7693]
Class Acc:
[0.9931 0.9257 0.9613 0.8223 0.7997 0.8289 0.8296 0.9068 0.9595 0.8469
0.9713 0.8988 0.7623 0.9731 0.9276 0.9282 0.878 0.8117 0.8631]
**W48 版本**
Images: 500 mIoU: 0.8206 Acc: 0.9677 Kappa: 0.9581
Class IoU:
[0.9855 0.8824 0.9373 0.6497 0.6827 0.7154 0.7584 0.8276 0.9317 0.6794
0.9545 0.8474 0.6691 0.9599 0.861 0.9099 0.8631 0.6784 0.7984]
Class Acc:
[0.993 0.9353 0.9669 0.8325 0.8434 0.8459 0.85 0.9186 0.9598 0.8376
0.9746 0.915 0.7899 0.9781 0.9423 0.9666 0.9425 0.8164 0.8812]
7. 推理可视化
还是以 U-HRNet-W18-small 为例,我们选用训练时的数据集配置和得到的最优模型。输出路径默认为 output/result。! bash predict.sh

图 6 - 原始图片


图 7 - 推理结果
8. 模型导出
导出推理模型
PaddlePaddle框架保存的权重文件分为两种:支持前向推理和反向梯度的训练模型 和 只支持前向推理的推理模型。二者的区别是推理模型针对推理速度和显存做了优化,裁剪了一些只在训练过程中才需要的tensor,降低显存占用,并进行了一些类似层融合,kernel选择的速度优化。因此可执行如下命令导出推理模型。
默认导出到 freezed_models 目录。! bash export_model.sh关于 PaddleSeg 的更多细节,可参考 PaddleSeg 全流程跑通
9. 模型部署
使用飞桨原生推理库paddle-inference,用于服务端模型部署
总体上分为三步:
创建PaddlePredictor,设置所导出的模型路径
创建输入用的 PaddleTensor,传入到 PaddlePredictor 中
获取输出的 PaddleTensor ,将结果取出
#include "paddle_inference_api.h"
// 创建一个 config,并修改相关设置paddle::NativeConfig config;
config.model_dir = "xxx";
config.use_gpu = false;// 创建一个原生的 PaddlePredictorauto predictor =
paddle::CreatePaddlePredictor<paddle::NativeConfig>(config);// 创建输入 tensorint64_t data[4] = {1, 2, 3, 4};
paddle::PaddleTensor tensor;
tensor.shape = std::vector<int>({4, 1});
tensor.data.Reset(data, sizeof(data));
tensor.dtype = paddle::PaddleDType::INT64;// 创建输出 tensor,输出 tensor 的内存可以复用std::vector<paddle::PaddleTensor> outputs;// 执行预测CHECK(predictor->Run(slots, &outputs));// 获取 outputs ...更多内容详见 > C++ 预测 API介绍


 微信联系
微信联系
