1 项目说明
课堂教学行为合规检查作为教务管理重要的一环,对提高教师教学质量,促进教评管理,深化教育改革均有重要意义。传统教学监督主要依靠人力完成,耗时耗力,效率低下。
新东方AI研究院针对该问题,利用飞桨PaddleDetection的目标检测技术,提出一种自动化检测方案,可以有效检测老师和学生的动作行为,帮助相关人员及时应对,对规范相关人员行为有重要意义,模型效果如图所示。

方案难点:
图片差异较大: 不同教室规格不同,摄像头安放位置也有差异,不同光线背景环境造成采集图像有明显的差异;
检测难度较大: 老师和学生动作较为隐蔽,学生人数较多,遮挡情况比较常见;
算法运行效率要求较高: 针对师生不规范的行为,应及时予以纠正,时效性要求高。
2 安装说明
环境要求
PaddlePaddle >= 2.2.0
Python >= 3.5
paddledet >= 2.3.0
本项目中已经帮大家下载好了最新版的PaddleDetection,无需下载,只需按下面步骤安装环境即可~# 安装环境
%cd /home/aistudio/work/paddlecode
!pip install -r requirements.txt
!python setup.py install
3 数据准备
本方案使用数据集由新东方各地培训学校教室搜集得到,老师动作检测数据集包含16913张图片,检测的动作类别为站立、坐着、写板书和玩手机,学生动作检测数据集包含11467张图片,检测的动作类型为练习、听讲、趴着、站立、举手和玩手机,示例图片如下图所示:


数据标注是通过labelImg标注而得到,如下图所示:
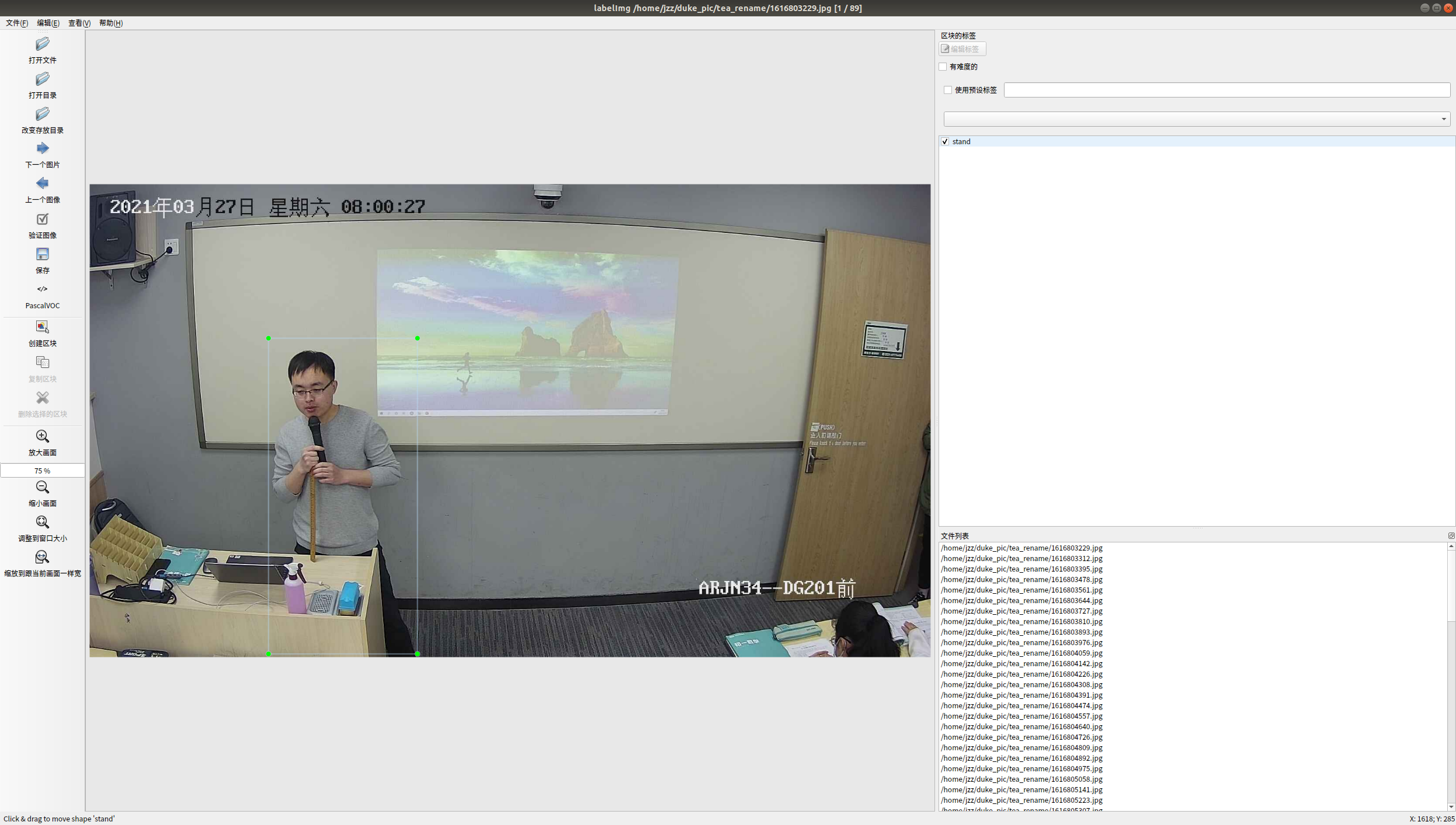
数据集图片格式是VOC数据格式,VOC数据是每个图像文件对应一个同名的xml文件,xml文件内包含对应图片的基本信息,比如文件名、来源、图像尺寸以及图像中包含的物体区域信息和类别信息等。
xml文件中包含以下字段:
filename,表示图像名称。
size,表示图像尺寸。包括:图像宽度、图像高度、图像深度。
1920 1080 3
object字段,表示每个物体。包括:
标签 说明 name 物体类别名称 pose 关于目标物体姿态描述(非必须字段) truncated 如果物体的遮挡超过15-20%并且位于边界框之外,请标记为 truncated(非必须字段)difficult 难以识别的物体标记为 difficult(非必须字段)bndbox子标签 (xmin,ymin) 左上角坐标,(xmax,ymax) 右下角坐标,
本方案中所使用的数据集路径为 /home/aistudio/work/paddlecode/voc_duke/ 读者无需做额外处理即可使用,由于涉及公司敏感信息,本此开源数据集仅包含626张老师动作检测图片,若有相关需求,请咨询新东方人工智能研究院。
将这626张图片随机切分,切分后包含400张图片的训练集和226张图片的测试集,数据集包含以下文件夹和文件:JPEGImages,Annotations,label_list.txt, train.txt和 test.txt,分别图片文件夹、xml标注文件夹、检测类别信息、训练样本列表、测试样本列表。训练样本列表和验证样本列表的每一行格式为:图片路径 对应的xml路径,例如VOCdevkit/VOC2007/JPEGImages/132_211_055.jpg VOCdevkit/VOC2007/Annotations/132_211_055.xml。
最终数据集文件组织结构为:
├── dataset ├──VOCdevkit │ ├──VOC2007 │ ├── Annotations │ │ ├── 000001.xml │ │ ├── 000002.xml │ │ ├── 000003.xml │ │ | ... │ ├── JPEGImages │ │ ├── 000001.jpg │ │ ├── 000003.jpg │ │ ├── 000003.jpg │ │ | ... ├── label_list.txt ├── train.txt └── valid.txt
4.模型选择
PaddleDetection提供了很多目标检测模型,考虑到不同模型精度、速度以及之后的部署便利性,本方案采用PP-YOLOv2作为服务端模型,PP-PicoDet作为移动端模型。
YOLOv3:Joseph Redmon等人在2015年提出YOLO(You only Look Once,YOLO)算法,通常也被称为YOLOv1;2016年,他们对算法进行改进,又提出YOLOv2版本;2018年发展出YOLOv3版本。YOLOv3使用单个网络结构,在产生候选区域的同时即可预测出物体类别和位置,这类算法被称为单阶段目标检测算法。另外,YOLOv3算法产生的预测框数目比Faster R-CNN少很多。Faster R-CNN中每个真实框可能对应多个标签为正的候选区域,而YOLOv3里面每个真实框只对应一个正的候选区域。这些特性使得YOLOv3算法具有更快的速度,能到达实时响应的水平。
PP-YOLO:PP-YOLO是PaddleDetection优化和改进的YOLOv3的模型,在COCO test-dev2017数据集上精度达到45.9%,在单卡V100上FP32推理速度为72.9 FPS,V100上开启TensorRT下FP16推理速度为155.6 FPS。PP-YOLO从如下方面优化:
更优的骨干网络: ResNet50vd-DCN
更大的训练batch size: 8 GPUs,每GPU batch_size=24,对应调整学习率和迭代轮数
更优的预训练模型
PP-YOLOv2:相较20年发布的PP-YOLO,PP-YOLOv2版本在COCO 2017 test-dev上的精度提升了3.6个百分点,由45.9%提升到了49.5%;在640*640的输入尺寸下,FPS达到68.9FPS。 主要改进点:
Path Aggregation Network
Mish Activation Function
Larger Input Size
IoU Aware Branch
PP-PicoDet:在当前移动互联网、物联网、车联网等行业迅猛发展的背景下,边缘设备上直接部署目标检测的需求越来越旺盛。生产线上往往需要在极低硬件成本的硬件例如树莓派、FPGA、K210 等芯片上部署目标检测算法。如何在尽量不损失精度的前提下,获得体积更小、运算速度更快的算法呢?更适用于移动端的PP-PicoDet由此诞生,PP-PicoDet特色如下:
精度高:PicoDet-S仅1M参数量以内,416输入COCO mAP达到30.6;PicoDet-L仅3.3M参数量以内,640输入COCO mAP达到40.9。是全网新SOTA移动端检测模型。
速度快:PicoDet-S-320在SD865上可达150FPS;PicoDet-L-640模型接近服务器端模型精度前提下,在移动端可达20FPS实时预测。
部署友好:支持Paddle Inference、Paddle Lite;支持快速导出为ONNX格式,可用于Openvino、NCNN、MNN部署;支持Python、C++、Android 部署。
5 模型训练
为提高检测效率,本方案移动端采用PP-PicoDet检测模型,服务端采用PP-YOLOv2作为检测模型,模型训练需要经过如下环节:
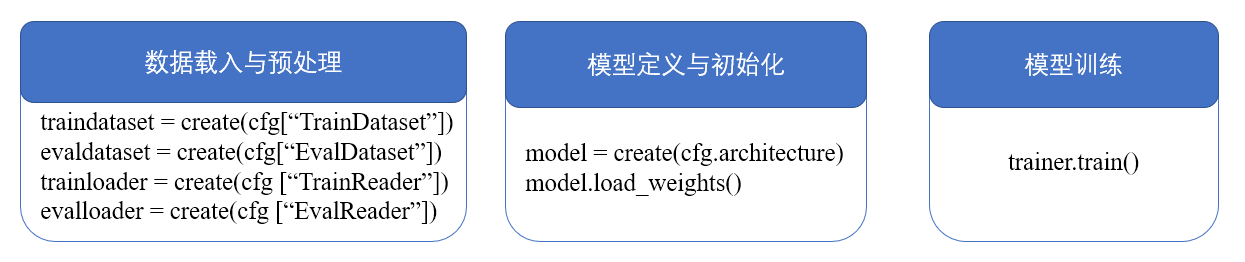
具体代码请参考train.py与ppyolov2_reader.yml,可修改参数:
TrainDataset:训练集所在目录,训练图片与标签列表;
evalDataset:测试集所在目录,训练图片与标签列表;
TrainReader:训练预处理参数,可以增加、修改数据增强方法和参数;
evalReader:测试预处理参数,可以增加、修改数据增强方法和参数;
architecture:检测模型结构,包含backbone、neck、head和post_process;%cd /home/aistudio/data/data131575/
%unzip data.zip
%mv ./data/voc_duke/ /home/aistudio/work/paddlecode/
%mv ./data/finetune_model/ /home/aistudio/work/paddlecode/
#GPU训练
%cd /home/aistudio/work/paddlecode/
#通过修改yml配置文件来训练不同结构检测模型
#服务端ppyolov2模型训练
!python -m paddle.distributed.launch --log_dir=./ppyolo_dygraph/ --gpus 0 tools/train.py -c configs/ppyolo/ppyolov2_r50vd_dcn_voc_tea.yml
#移动端PicoDet模型训练
!python -m paddle.distributed.launch --log_dir=./ppyolo_dygraph/ --gpus 0 tools/train.py -c configs/picodet/picodet_s_640_voc_tea.yml
6 模型评估
本方案采用MAP作为评价标准,测试命令如下:%cd /home/aistudio/work/paddlecode/
#通过修改yml配置文件与模型文件目录来测试不同模型
#服务端ppyolov2模型评估
!CUDA_VISIBLE_DEVICES=0 python tools/eval.py -c
configs/ppyolo/ppyolov2_r50vd_dcn_voc_tea.yml -o
weights=output/ppyolov2_r50vd_dcn_voc_tea/best_model
#移动端PicoDet模型评估
!CUDA_VISIBLE_DEVICES=0 python tools/eval.py -c
configs/picodet/picodet_s_640_voc_tea.yml -o
weights=output/picodet_s_640_voc_tea/best_model
7 模型预测
加载训练好的模型,默认置信度阈值设置为0.5,执行下行命令对验证集或测试集图片进行预测:# 推理单张图片
!CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyolo/ppyolov2_r50vd_dcn_voc_tea.yml -o weights=output/ppyolov2_r50vd_dcn_voc_tea/best_model.pdparams --infer_img=demo/tea_rename/1616810135.jpg
#推理文件夹里全部图片
!CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyolo/ppyolov2_r50vd_dcn_voc_tea.yml -o weights=output/ppyolov2_r50vd_dcn_voc_tea/best_model.pdparams --infer_dir=demo/tea_rename/ 可视化预测结果示例如下,可以看出老师动作可以有效检测出来:

8 模型导出
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型%cd /home/aistudio/work/paddlecode/
#paddle inference模型导出(移动端)
!python tools/export_model.py -c
configs/picodet/picodet_s_640_voc_tea.yml -o
weights=output/picodet_s_640_voc_tea/best_model.pdparams --output_dir
output_inference_mobile
#paddle serving 模型导出
!python tools/export_model.py -c
configs/ppyolo/ppyolov2_r50vd_dcn_voc_tea.yml -o
weights=output/ppyolov2_r50vd_dcn_voc_tea/best_model.pdparams
--export_serving_model=True --output_dir output_inference*
更多关于模型导出的文档,请参考PaddleDetection模型导出教程
9 模型部署推理
接下来使用Paddle Inference python高性能预测接口,在终端输入以下代码即可:# 移动端模型推理
!python deploy/python/infer.py
--model_dir=./output_inference_mobile/picodet_s_640_voc_tea/
--image_file=./demo/tea_rename/1616809969.jpg --device=GPU
#服务端模型推理
%cd /home/aistudio/work
!tar -xzvf TensorRT6-cuda10.1-cudnn7.tar.gz
##由于paddle serving需要额外依赖依赖 所以需要设置环境变量
!echo ‘export LD_LIBRARY_PATH=LDLIBRARYPATH:/home/aistudio/work/TensorRT6−cuda10.1−cudnn7/lib′>> /.bashrc!echo′exportLDLIBRARYPATH=LDLIBRARYPATH:/home/aistudio/work/TensorRT6−cuda10.1−cudnn7/lib′>> /.bashrc!echo′exportLDLIBRARYPATH=LD_LIBRARY_PATH:/home/aistudio/work/centos_ssl’ >> ~/.bashrc
!source ~/.bashrc
##开启服务
%cd /home/aistudio/work/paddlecode/output_inference/ppyolov2_r50vd_dcn_voc_tea
!python -m paddle_serving_server.serve --model serving_server --port 9392 --gpu_ids 0
#测试服务
%cd /home/aistudio/work/paddlecode/output_inference/ppyolov2_r50vd_dcn_voc_tea
!python …/…/deploy/serving/test_client.py …/…/voc_duke/voc_teacher/label_list.txt …/…/demo/tea_rename/1616809969.jpg
10 模型优化
本小节侧重展示在模型迭代过程中优化精度的思路,在本案例中,尝试以下优化策略来进行优化
10.1 模型优化策略
修改图片尺寸:数据处理时,可修改
target_size为512、608、640等学习率等训练参数的调整
数据增强:数据处理时,使用不同的预处理、增强方法组合,包含:AutoAugment、RandomFlip、RandomDistort、FlipWarpAffine、 RandomCrop、RandomExpand、Mixup等,详细代码请参考图像预处理/增强
不同模型:单阶段(YOLOv3、PP-YOLO、PP-YOLOv2等)
不同backbone:ResNet50、ResNet101、DarkNet53、MobileNet3,不同necks:YOLOv3FPN、PPYOLOFPN、PPYOLOTinyFPN、PPYOLOPAN。这些可以通过修改yml网络配置文件来实现
YOLOv3: backbone: ResNet neck: PPYOLOPAN yolo_head: YOLOv3Head post_process: BBoxPostProcess ResNet: depth: 50 variant: d return_idx: [1, 2, 3] dcn_v2_stages: [3] freeze_at: -1 freeze_norm: false norm_decay: 0. PPYOLOPAN: drop_block: true block_size: 3 keep_prob: 0.9 spp: true
不同损失函数的组合,该项配置也可以通过修改yml网络配置文件来实现
YOLOv3Loss: ignore_thresh: 0.7 downsample: [32, 16, 8] label_smooth: false scale_x_y: 1.05 iou_loss: IouLoss iou_aware_loss: IouAwareLoss IouLoss: loss_weight: 2.5 loss_square: true IouAwareLoss: loss_weight: 1.0
10.2 不同模型结果
我们修改不同配置文件,进行如下实验进行动作检测模型初步优化
| 序号 | 模型 | V100 FP32(FPS) | MAP(%) |
|---|---|---|---|
| 1 | PP-YOLO+ResNet50+ImageNet预训练(baseline) | 63 | 80.1 |
| 2 | PP-YOLOv2+ResNet50+ImageNet预训练 | 51 | 84.2 |
| 3 | PP-YOLOv2+ResNet50+COCO预训练 | - | 85.6 |
| 4 | PP-YOLOv2+ResNet50+COCO预训练+aug | - | 86.8 |
| 5 | PP-YOLOv2+ResNet50+COCO预训练+aug* | - | 87.3 |
| 6 | PP-YOLOv2+ResNet50DCN+COCO预训练+aug* | - | 87.6 |
| 7 | PP-YOLOv2+ResNet50DCN+COCO预训练+aug*+SPP=False | - | 86.2 |
| 8 | PP-YOLOv2+ResNet50DCN+COCO预训练+aug*+PPYOLOPAN | - | 88.2 |
| 9 | PP-YOLOv2+ResNet50DCN+COCO预训练+aug*+PPYOLOPAN+学习率余弦衰减 | - | 89.3 |
移动端模型
| 序号 | 模型 | V100 FP32(FPS) | MAP(%) |
|---|---|---|---|
| 1 | PP-PicoDet-S+COCO预训练 | 111 | 78.4 |
| 2 | PP-PicoDet-S+COCO预训练+aug* | - | 81.8 |
| 3 | PP-PicoDet-S+COCO预训练+aug*+学习率余弦衰减 | - | 83.5 |
| 4 | PP-PicoDet-M+COCO预训练+aug*+学习率余弦衰减 | 95 | 84.3 |
| 5 | PP-YOLO-tiny+COCO预训练+aug*+学习率余弦衰减 | 166 | 68.1 |
| 6 | PP-YOLO-Mobilenetv3-small+COCO预训练+aug*+学习率余弦衰减 | 172 | 75.4 |
| 7 | PP-YOLOv2-Mobilenetv3-large+COCO预训练+aug*+学习率余弦衰减 | 143 | 76.2 |
说明:
aug数据增强方式有Mixup、RandomDistort、RandomExpand、RandomCrop和RandomFlip,aug*指的是在常用数据增强方式基础上加入多尺度训练
PP-YOLO模型推理速度测试采用单卡V100,batch size=1进行测试,使用CUDA 10.2, CUDNN 7.5.1
各模型推理尺度都为640尺度
PP-YOLO模型FP32的推理速度测试数据为使用
tools/export_model.py脚本导出模型后,使用deploy/python/infer.py脚本中的--run_benchnark参数使用Paddle预测库进行推理速度benchmark测试结果, 且测试的均为不包含数据预处理和模型输出后处理(NMS)的数据(与YOLOv4(AlexyAB)测试方法一致)。本实验结果是在1186张测试图片的结果,由于涉及公司敏感信息,图片暂未开源,读者可以在开源的626张图片中尝试训练与测试。
模型优化思路:
1.通过选择更好的检测架构可以提高检测的Recall值——即Neck,Head部分的优化可以提高Recall。<YOLOv3 到 PP-YOLOv2>
2.添加数据增强有效提高精度。
3.在数据量比较少的情况下,可以增加预训练模型。
通过以上的简单优化方式,本方案模型选取如下:
| 移动端模型 | V100 FP32(FPS) | MAP(%) |
|---|---|---|
| PP-PicoDet-S+COCO预训练+aug+学习率余弦衰减 | 111 | 83.2 |
| 服务端模型 | V100 FP32(FPS) | MAP(%) |
|---|---|---|
| PP-YOLOv2+ResNet50DCN+COCO预训练+aug+PPYOLOPAN+学习率余弦衰减 | 51 | 89.3 |
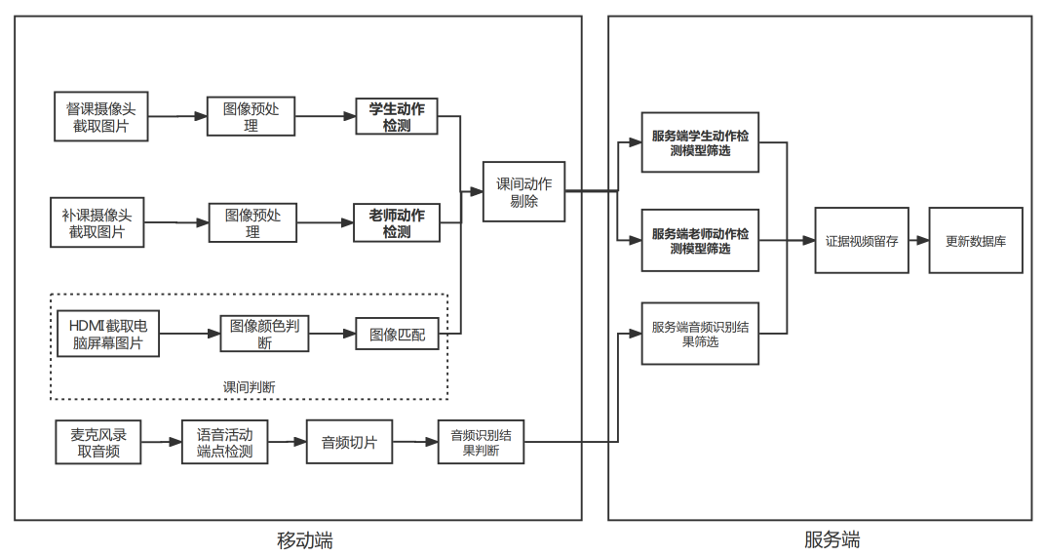
11 督课整体方案


 微信联系
微信联系
